For additional guidance, check out our community articles detailing the process of migrating from your current platform to Carbonio CE.
For enterprise-level requirements and advanced features, consider checking out Zextras Carbonio – the all-in-one private digital workplace designed for digital sovereignty trusted by the public sector, telcos, and regulated industries.
In recent years, IT’s progressive increase has made HA systems popular in industries that their income directly relies on their user’s satisfaction and system availability. Hospitals and data centers that require high availability of their systems to perform daily activities also hugely benefit from HA systems.
Zextras High Availability for Zimbra Servers
High availability (HA) is an essential characteristic of a system. Traditionally high availability systems consist of a set of loosely coupled servers with failover capabilities. This is far from being perfect. Zextras has tried to overcome every drawback of simple traditional approaches by introducing new methods and concepts to make Zimbra an extremely efficient HA system. Replication and Heartbeat technologies are two examples.
How Zextras High Availability Works
We can achieve HA through different approaches based on fail tolerance. Zextras achieved this goal using the application approach, as opposed to hardware and operating system approaches.
- Hardware (VSAN, clustered hardware) – When several machines write on the same disk.
- Operating system (DRDB + vIP) – Like above, OS writes on different physical disks without.
- Application – This approach is far more intelligent and considers what is happening to the files.
Application Approach
Using the application approach was a revolutionary change. This smart nature improves the availability of servers equipped with the Zextras extensively, which is more economical than other methods.
The main advantage of the application approach over the other two methods is that it considers what happens to the files. The other two methods don’t care about the essence of the operation and continue to replicate it over all the nodes.
- In the hardware approach, when you delete the file from the disk, it is replicated on other instances using the same disk no matter what.
- In the operating system approach, when you delete the file from one physical disk, the OS doesn’t care and does the same operation on the second one as well.
- In the application approach, you know what is supposed to happen to which data and decide which operations should be replicated, which files can be altered, and which accounts should have HA. For example, you know if it’s a log or temp file, or maybe it’s something that the application shouldn’t alter, such as removing one file or encryption at a low level.
Bacis Concepts
To better understand how Zextras achieves high availability, we need to know how high availability basic concepts such as eliminating the single points of failure are applied to a Zimbra environment.
Let’s see how these concepts exert in Zimbra components; LDAP, proxy, MTA, and Memcached.
- Elimination of single points of failure – Having more than one server to do the same service. We should have the possibility of installing each component of the infrastructure more than once so that failure of a component does not mean failure of the entire system. e.g., Having multiple MTA so if one MTA goes down, we won’t lose the main queue. Mailboxes are a single point of failure.
- Reliable crossover – In redundant systems, the crossover point itself becomes a single point of failure.
- Failover – It is a backup operational mode in which a secondary system assumed the functions of a system component if the primary one goes offline. In this case, users may never see a failure; however, the maintenance mechanism must observe that. It can be managed via a DNS or an internal load balancer. Your system can have interruptions, like when users need to refresh the page but don’t lose anything. The system does that automatically, and no admin action is required.
We can simplify Zextras high availability design into this diagram:
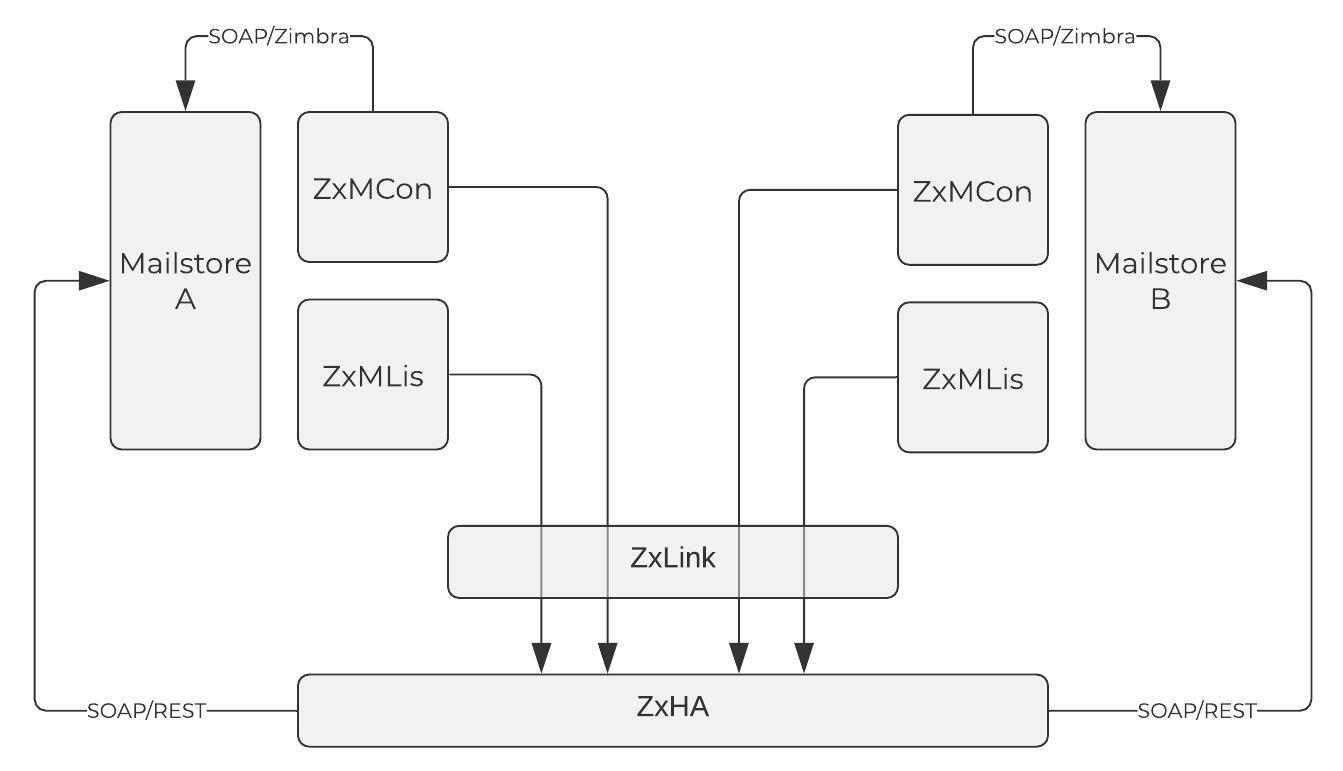
Service Granularity
All the components are in multiple instances and redundancy. All the apps in our mailstores use soap calls to do operations such as uploading, downloading, sending messages, changing status, etc. There are two essential components:
- A listener (ZxMLis) – Each node has its listener that copies the same operation performed in the mailstore into a bus (ZxHA) shared between them.
- A consumer (ZxMCon) – Each node has a consumer that reads the operations queue stored in ZxHA and performs them on its mailbox. It simulates the user interactions.
Zextras uses this design to let you choose which operations, accounts, and COS can use high availability. For instance, some computationally intensive operations such as indexing can be excluded from HA, so each server performs them using its own resources. This way, we intensely reduce the number of bytes sent to the bus.
Independency
The whole process is autonomous (independent from the store). It means that if mailstore A sends information to the bus regardless of the mailstore B status. Even if the mailstore B was offline when the operation is stored, it could read the bus whenever available. Alternatively, B can read the operations stored in the bus even if the A is not available. The system can recreate every operation because all the necessary information is available on the bus.
Speed
Since this bus is based on a memory map, it’s fast. Technically speaking, there are two different concepts when it comes to storing data.
- Storing the metadata,
- Storing the physical object.
The same concept is used in designing our central storage. The file uploaded in A can be available in B simply by reporting its ID.
Balancer
Zextras HA uses a balancer which is a typical solution used in HA. The balancer looks to see if the proxy or MTA are working then redirects the account to one service or another. Each account works in its own store. For instance, in the figure, store2 will store every change in a file. Blobs are saved on a bucket, and the consumer sends all the operations and the metadata to the Kafka infrastructure available on both servers. Therefore, if store2 is not available, the balancer redirects all the operations on store2 to store3, and we switch the account from store2 to store3. The balancer on top of the figure decides to forward the flow from unavailable stores to available ones.
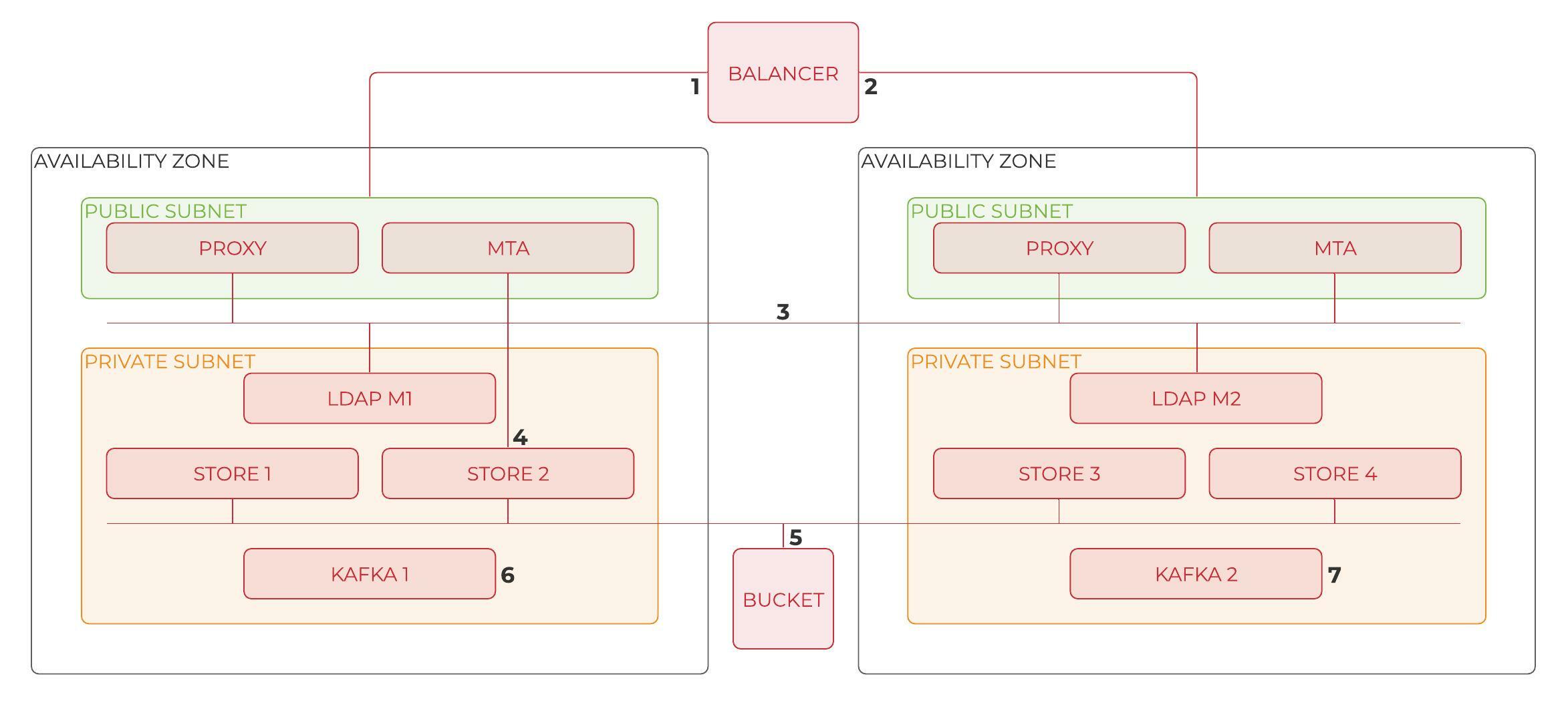
- The user connects to the first available proxy by browsing the webmail address,
- The incoming email goes through the first available MX,
- All frontend servers are connected,
- All the operations are done on the account’s mailstore,
- Blobsstored in the centralized volume,
- Listener intercepts all the metadata changes and forwards the information to the message broker,
- Consumer updates the account’s replicas.
Geographical Distribution
Geographical distribution of the nodes is another significant aspect of this design, which means there is no need to have the whole infrastructure on the same physical network (some servers can be in Rome and some in London).
Avoid Replicating Errors
This approach also lets you avoid replicating application errors. For example, the mailstore gets corrupted because of a wrong update. We can prevent replicating these errors into other services simply by excluding these operations. This is possible thanks to the application approach that allows you to indicate which operations to replicate and which not.
More Economic
This approach also helps you to balance wisely. Let’s say you’re comparing different HA solutions for your infrastructure. Replicating all the infrastructure can be costly, depending on the size of your infrastructure. With Zextras HA, each store can be a replica of another one which is a lot more economical regardless of the size of your infrastructure. To understand better, consider the following scenarios:
- One way would be replicating all the infrastructure to prevent any slowdown or downtime. In situations with limited accounts, say only 1000 accounts, replicating all the infrastructure is not a big deal. However, if you have 20 stores, each with 100,000 accounts, replicating the infrastructure is not viable. It costs you a lot of money while most probably all the 20 stores will go down simultaneously.
- Another solution would be Zextras HA. In our approach, each store could potentially be a replica of another one. Let’s say you have 100,000 accounts on store A which are replicated on the other 19 stores (4000 accounts on one store and 6000 on another, and so on). Therefore, each store acts as a peer creating a mesh.
Replication Technology
The great thing about Zextras HA is that depending on how big your infrastructure is and how capable your stores are, you might lose many stores before the whole infrastructure is considered at fault. Having this mesh structure is another advantage of the application approach. For instance, let’s say you have 3 servers and 4 accounts using the application approach. Having an account on a server is specified as active. Standby means that the account is replicated on that server. Considering this method, you can at least lose half of the servers without impacting the infrastructure.
| Account 1 | Account 2 | Account 3 | Account 4 | |
|---|---|---|---|---|
| Server 1 | Active | Active | Standby | Active |
| Server 2 | Standby | Standby | Active | |
| Server 3 | Standby |
You can also choose which accounts to be replicated based on their importance. (Note that it’s different from having a backup, this technology aims to have multiple copies on other servers that are all available.)
Heartbeat Technology
To put it simply, Heartbeat lets the server understand if there are issues in the application. For example, consider only using the replication technology; if a server goes down, everything will work as expected to prevent the halt. But sometimes, the server is not available even if it’s still live. For example, it replies too slow or responds with metadata because of corruption in the data. Therefore, having a component that monitors how fast the server replies based on the CPU or memory loads helps avoid such slowdowns. This technology predicts the fault of the server before the server goes down. This is more similar to the fault tolerance concept because it recognizes that fault is coming and helps you handle the situation before the fault. The other point of Heartbeat technology is to understand the heavy load to help distribute the load. For example, you have a working server, but every account starts to do CPU-intensive or disk-intensive tasks. In this case, the administrator prefers to be informed to perform load balancing by splitting the accounts into other servers (not into another server; otherwise, that server would fault under heavy load) to reduce the load (this is not yet implemented).
FAQ
Is It Stateless?
HA concept exists for a long time, but the infrastructure itself and making the operations stateless are more complicated. One common question one might ask could be about statelessness. This is not yet a stateless system that doesn’t care about availability. Our mailbox is still stateful with multiple instances, and you have to balance the instance while making the instance transparent to the user. There is also no other stateless alternative in the Zimbra world.
Other Players?
Other players have similar technologies. For instance, Microsoft Exchange has something called distribution groups technology, allowing the Exchange servers to share information. Domino servers have a similar concept as well. The main difference between these technologies and Zextras HA is the bus we implemented. For example, in Exchange, if you have slow replication for some reason, it would be possible that the main server goes down or faults before the replication ends, which causes the latest window to be lost. However, the Zextras HA bus is independent of the source and destination stores being available. Since the information is not stored on the source or the destination stores but an autonomous bus, as soon as the server is live, you can choose this server to read the information and become the master.