For additional guidance, check out our community articles detailing the process of migrating from your current platform to Carbonio CE.
For enterprise-level requirements and advanced features, consider checking out Zextras Carbonio – the all-in-one private digital workplace designed for digital sovereignty trusted by the public sector, telcos, and regulated industries.
How we made the restore performance 20 times faster!
As Product Owner of Backup, I’m thrilled to announce that with release 3.1.11, a redesigned and faster External Restore has been released.
Keeping the backward compatibility – as always – we improved the restore performance by x20 times! Therefore, we made the external restore a very reliable and fast process you can count on.
Restore process was designed to use less resource as it is possible, making the process a background operation that should never impact on service performance. However, email flow has changed (user mailbox are growing and users want to keep all the email in their mailboxes) as general server specs (more powerful processor and faster disk).
According to feedback provided by our customers, sys admins wanted to speed up the process, and make it able to use all the available resources.
The backup consist of 3 phases – provisioning, data restore, shares restore – and in order to achieve this goal, we rewrote the second phase, making it able to complete the restore process 20 times faster. To deep understand the 3 phases of the backup you can read the Zextras Backup article.
Let me explain a bit more deeper how the restore process works and how we reached this awesome goal.
As we previously discussed in this community, the backup is made up of two kind of objects:
- metadata, that describes how the items changes (their status, the folders in which they reside, their attributes)
- blobs, that physically contain the binary data of the object, in other words, the base64 EML.
Blobs requires the greatest part of the storage, but often are metadata that impact on backup performances. This because backups need to read states of each item, decode the metadata, build metadata dependencies (eg. folder stricture), read the blob, add the item to the user mailstore and update the map-file.
The best way to understand is by looking at the results of a series of tests we did. Consider that the backup works at “server” level: each server should be sized and analyzed by its own.
This was our test environment setup:
| ESX Version: | 6.7.0 Update 3 (Build 14320388) | ||
| Hardware | Dell PowerEdge R440 | ||
| CPU | Intel(R) Xeon(R) Silver 4208 CPU @ 2.10GHz |
| VM Spec | ||
| CPU | 4 vCPU | |
| RAM | 16 gb | |
| Volume 1 | 124 gb – /dev/sda – EXT | / |
| Volume 2 | 100 gb – /dev/sdb – XFS | /backup |
| Volume 3 | 100 gb – /dev/sdc – XFS | /opt/zimbra-index |
| Volume 4 | 100 gb – /dev/sdd – XFS | /backup-to-restore |
| OS | Linux | Ubuntu 18.04.5 LTS |
| Zimbra version | 8.8.15.GA FOSS edition | Patch 8.8.15_P19 |
For further test there were also 2 S3 buckets
- one S3 Bucket for centralized Storage
- one S3 Bucket for Backup on external Storage
A Prometheus agent has been installed on the virtual machine, sending the collected data on a Grafana portal.
First we stressed the metadata management, by flooding the server with 15.000.000 small emails of few Kbs: basically only plaintext messages. This scenario was intended to generate a huge number of database rows and backup states, despite of the overall quota.
Once the server was flooded , a smartscan deep was executed and all the accounts and domain were deleted from the source host. The backup composition for the test case was:
| Group | Num of accounts | Num of items |
| A | 1 | 1.450.000 |
| B | 32 | 270.000 |
| C | 32 | 105.000 |
| D | 5 | 21.000 |
| E | 10 | 9.000 |
| F | 30 | 4.500 |
Then the generated backup was mounted under the /backup-to-restore mountpoint.
To speed up the restore operation the following services had been stopped: AntiVirus, AntiSpam, OpenDKIM.
Test1 – External Restore single account
In order to realize a test environment similar to a real use case, all the volumes were limited to 200 IOPS.
We decided to import a single account with 270.000 emails for this test: more or less a user older than five years that sent and received more than 100 emails each day.
| 3.1.10 | 3.1.11 | |
| Operation_id | 141f6481-c989-4b8a-a021-634e477db85f | eef836d6-c087-4e39-9277-375da7308579 |
| Elapsed | 1 day, 17 hours, 6 minutes, 29 seconds | 2 hours, 1 minute, 47 seconds |
| Accounts | 1 | 1 |
| Items | 270378 | 270380 |
| Items/Sec | 1.82701417 | 37.0028739564801 |
| CPU | 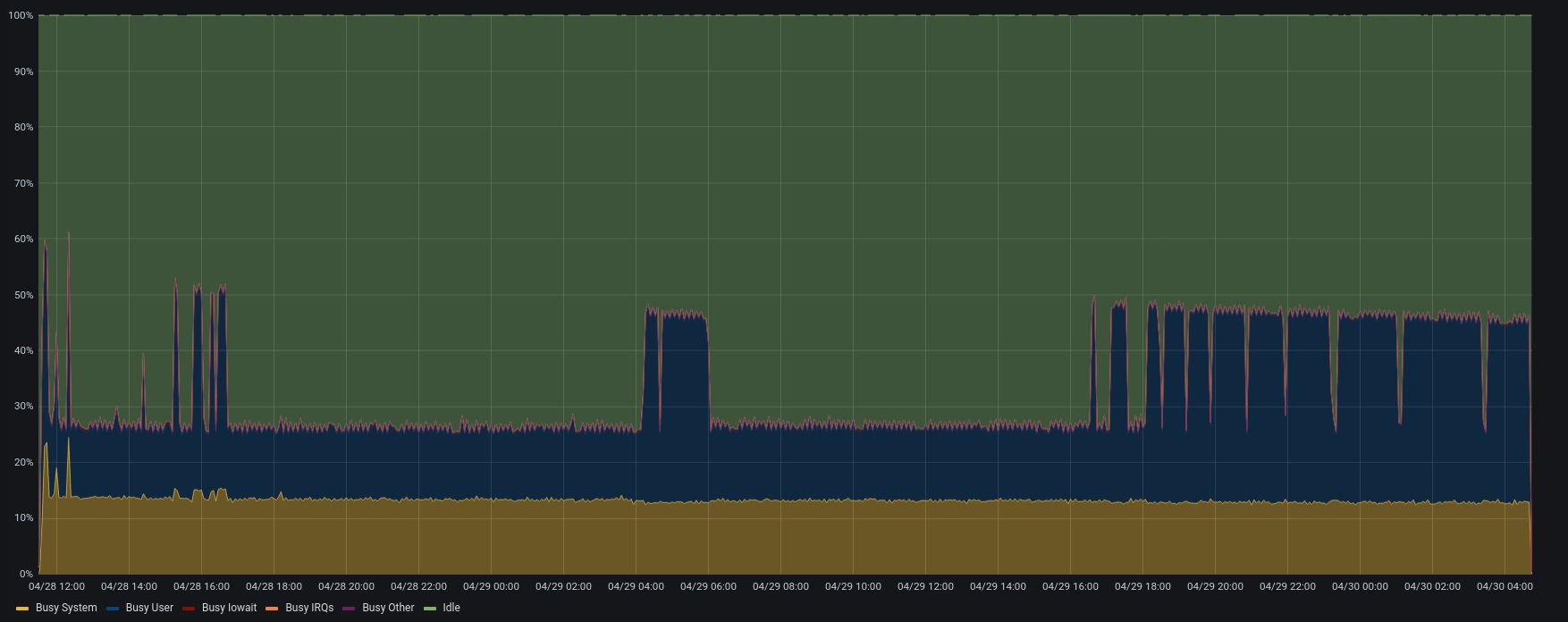 | 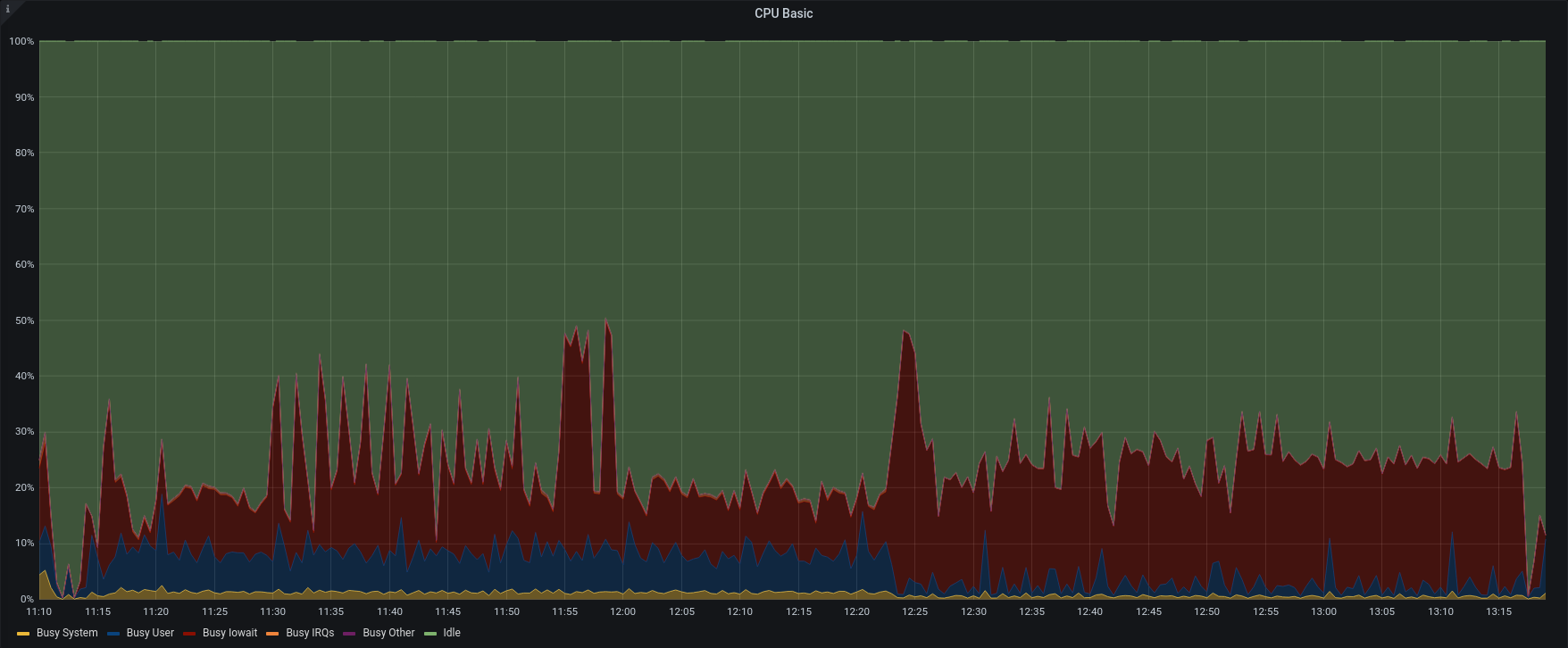 |
| Memory | 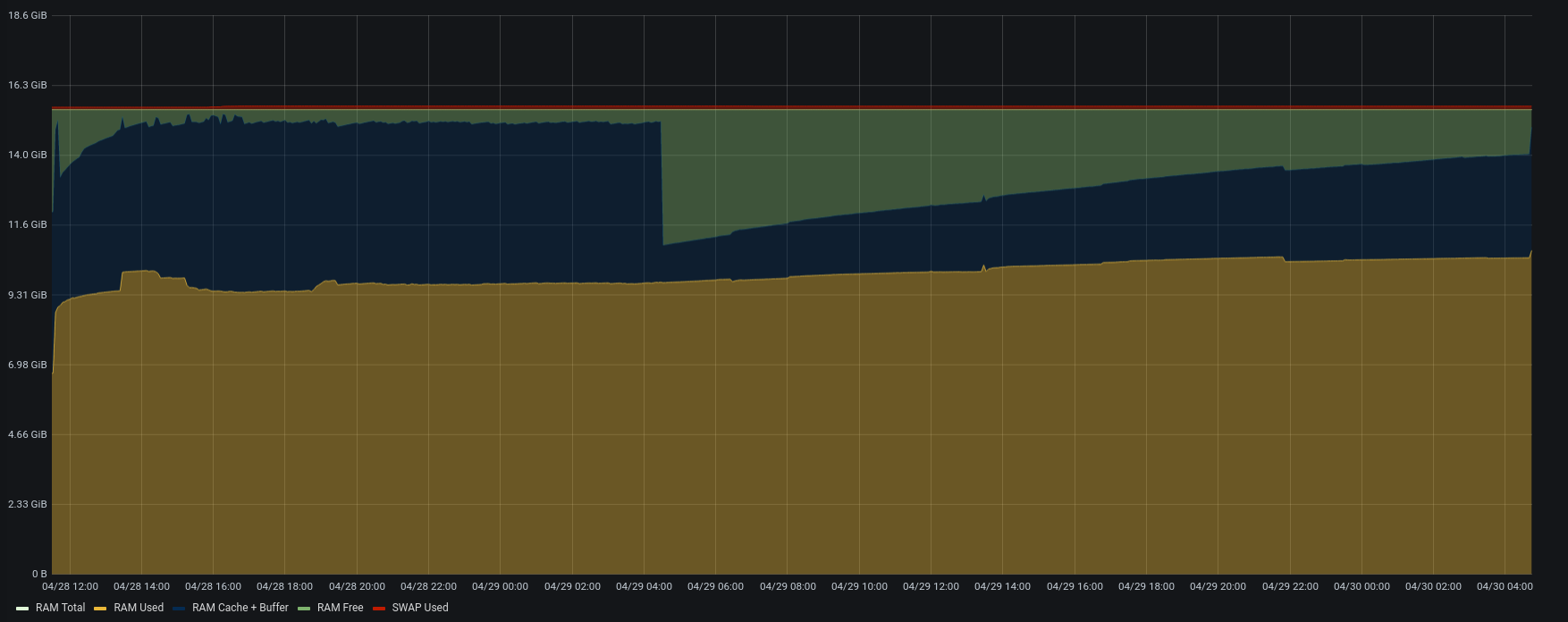 | 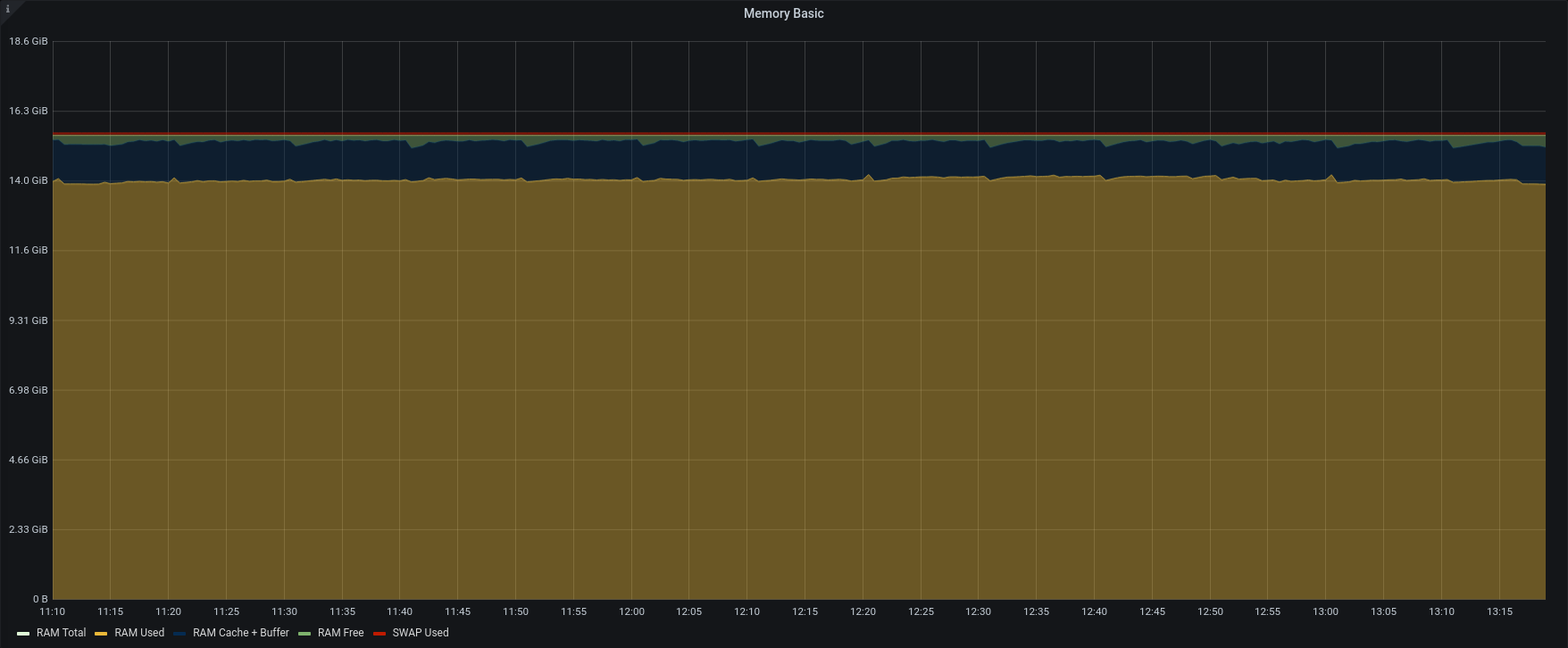 |
| HeapSize | 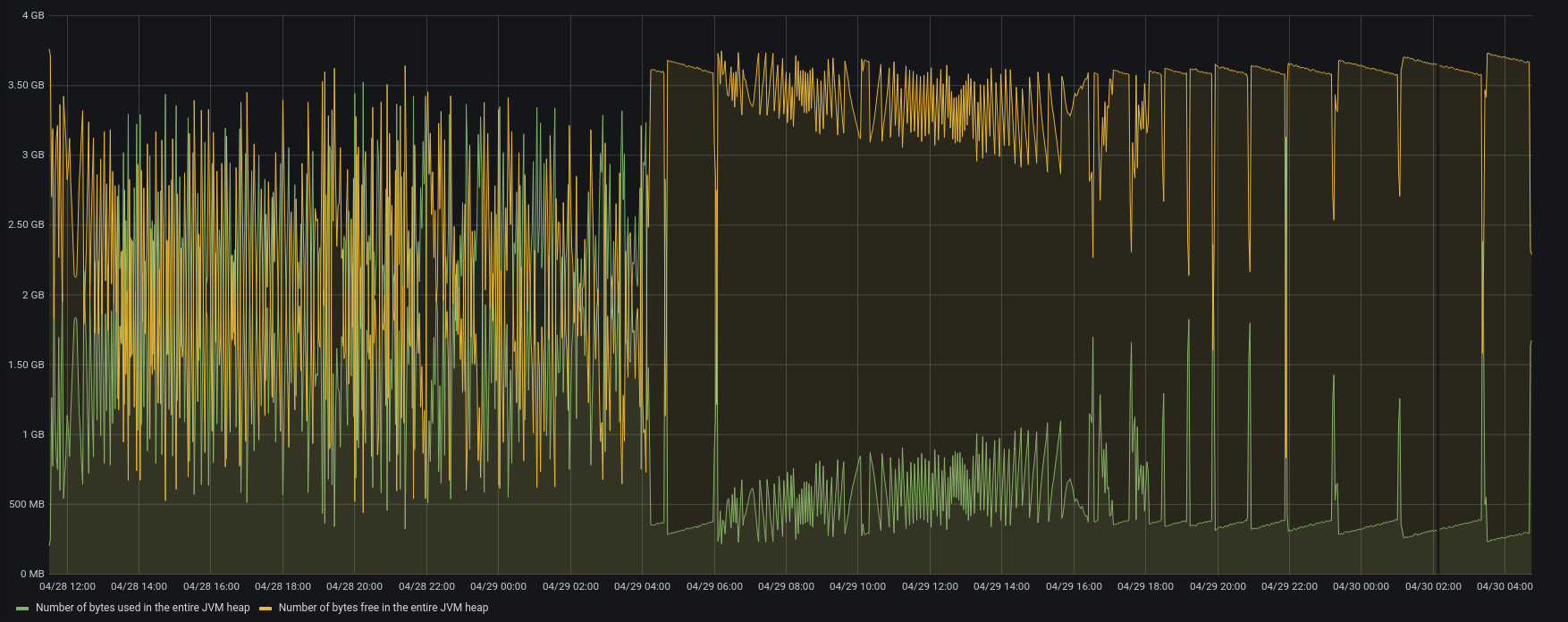 | 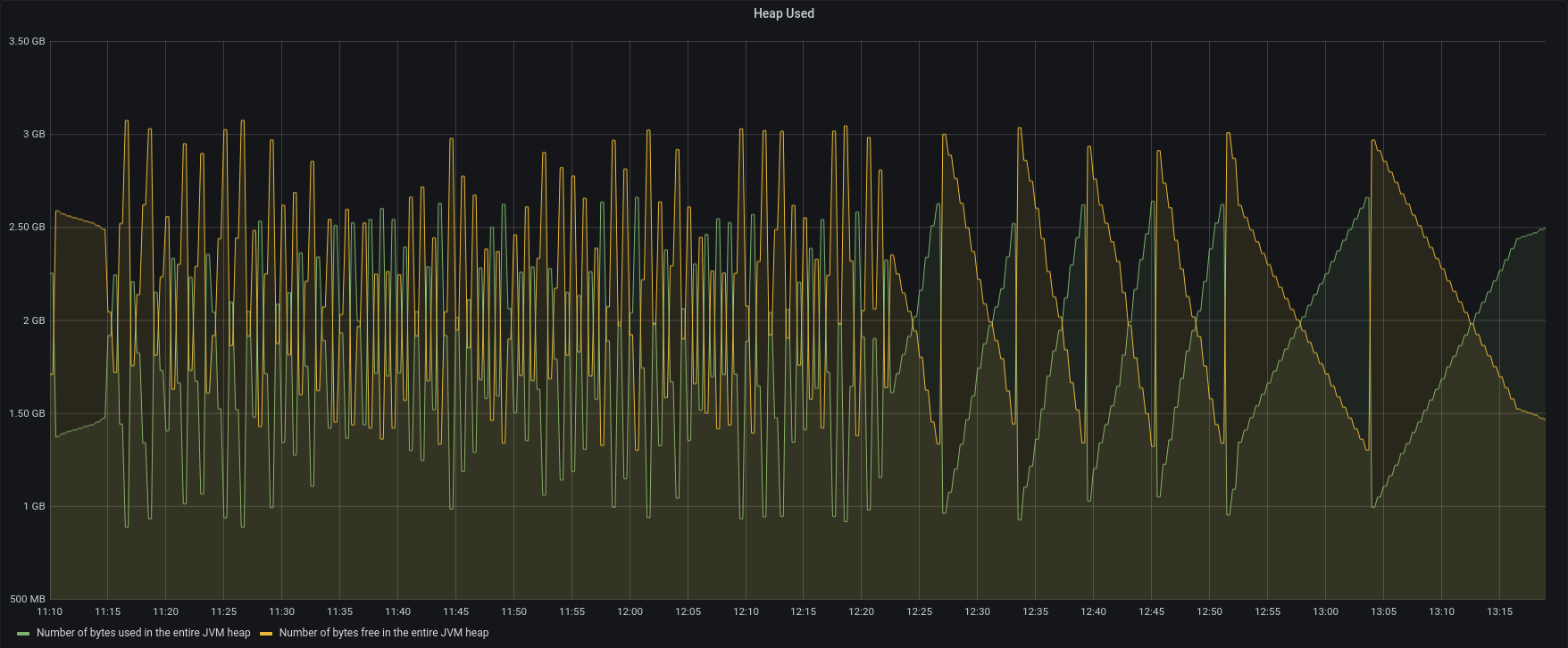 |
| IOPS | 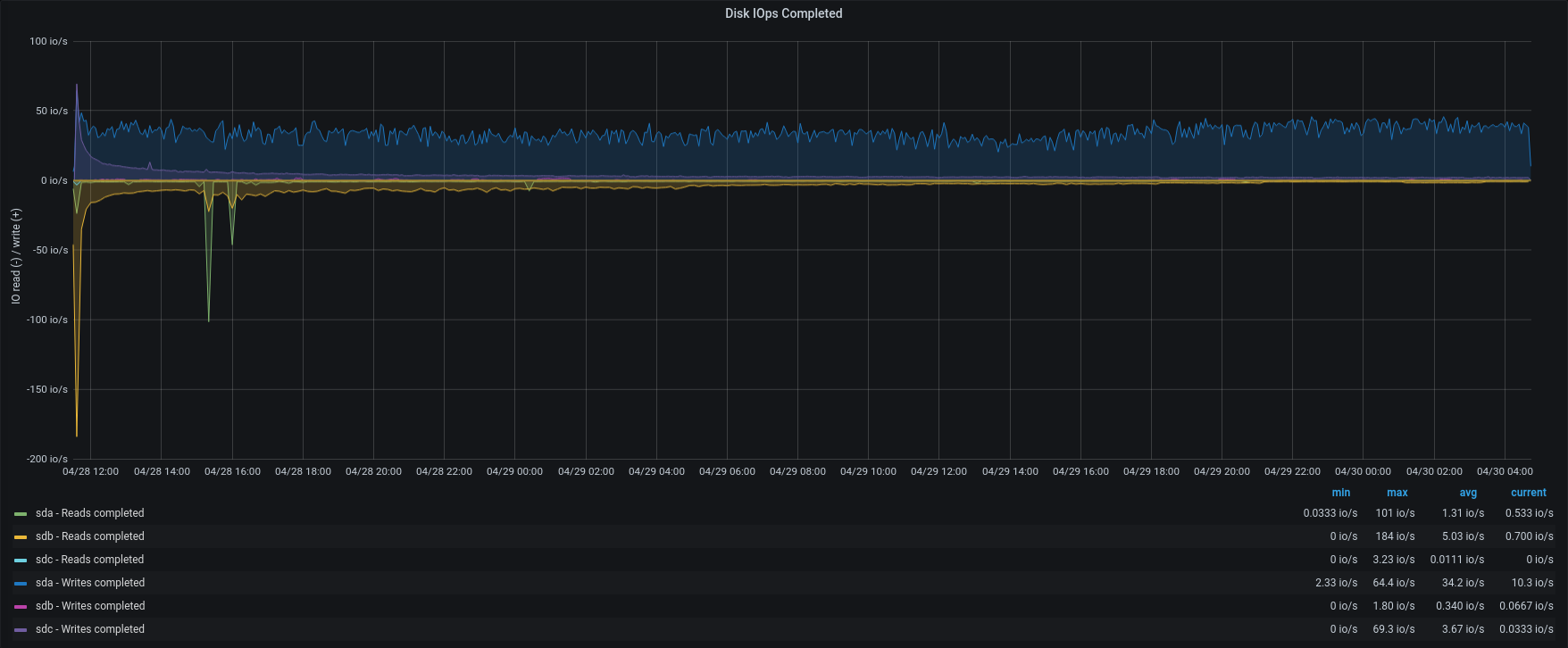 | 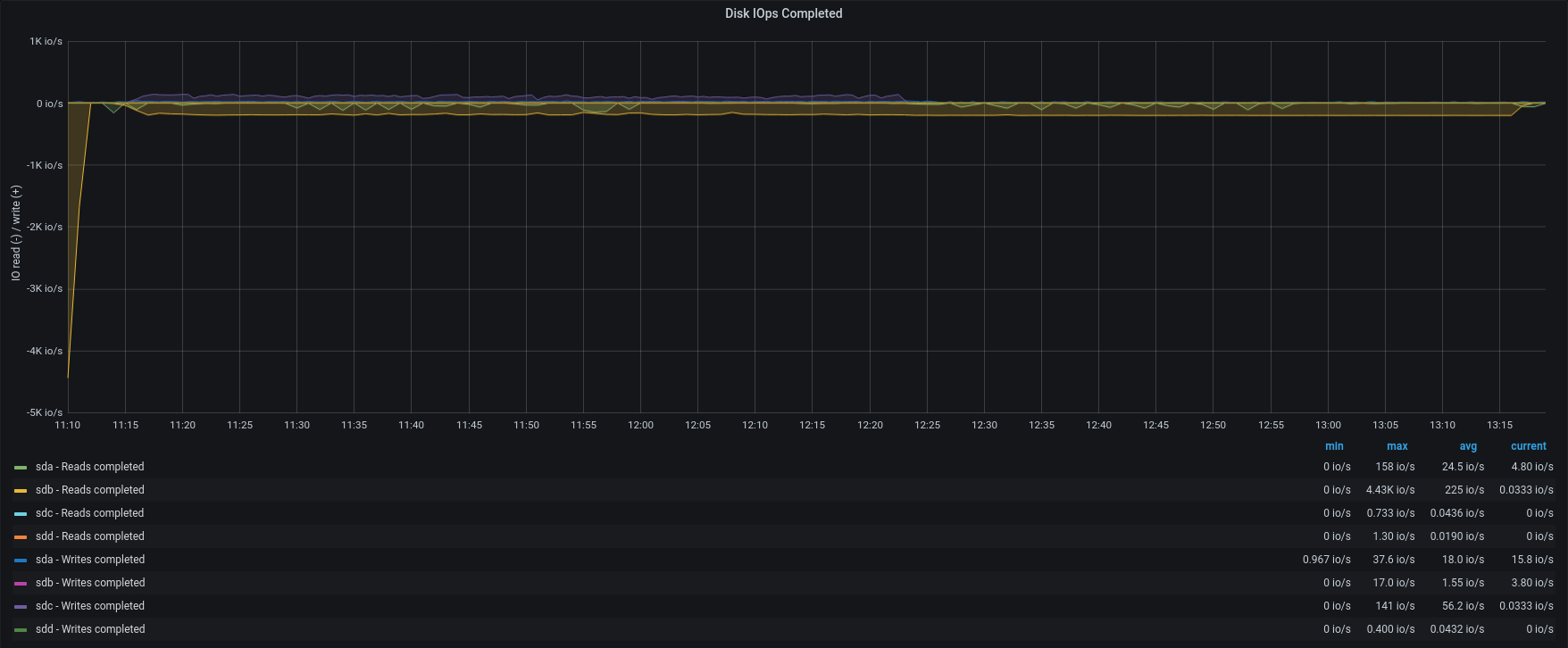 |
| Disk R/W | 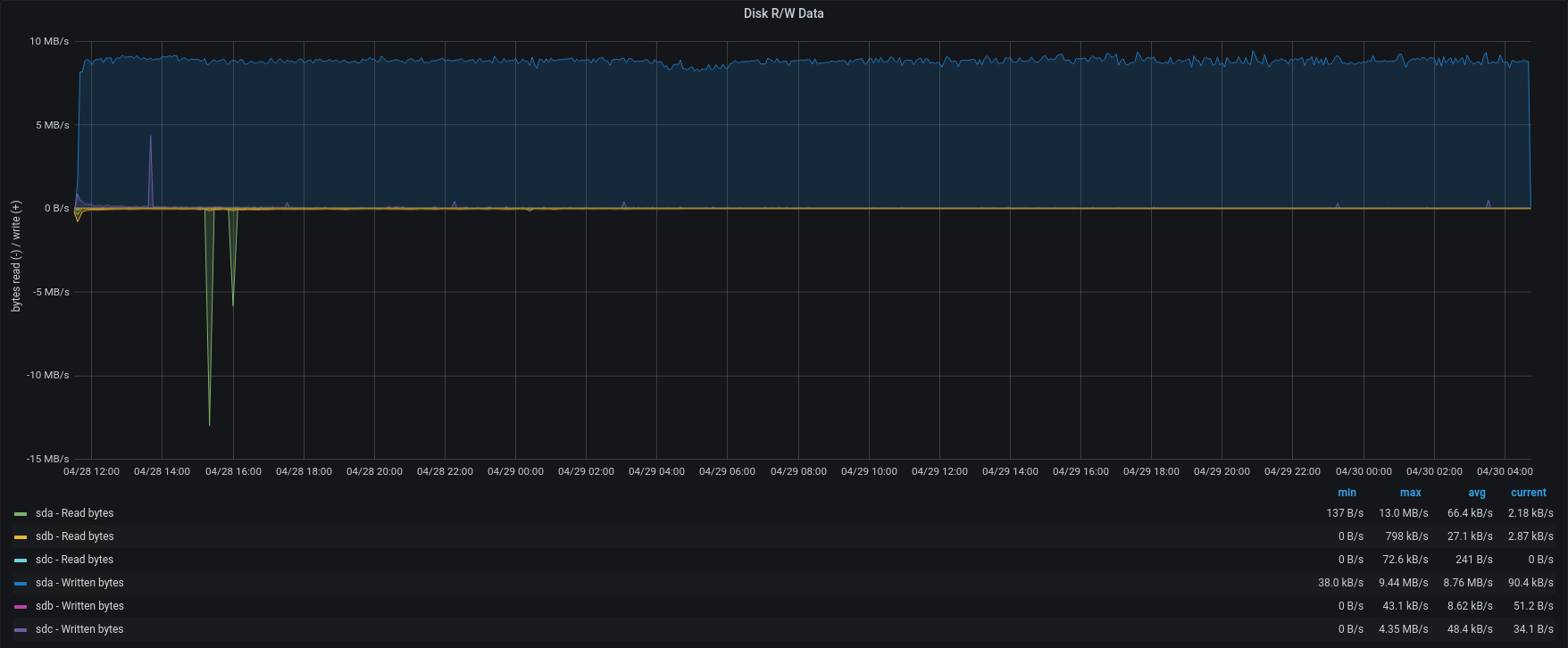 | 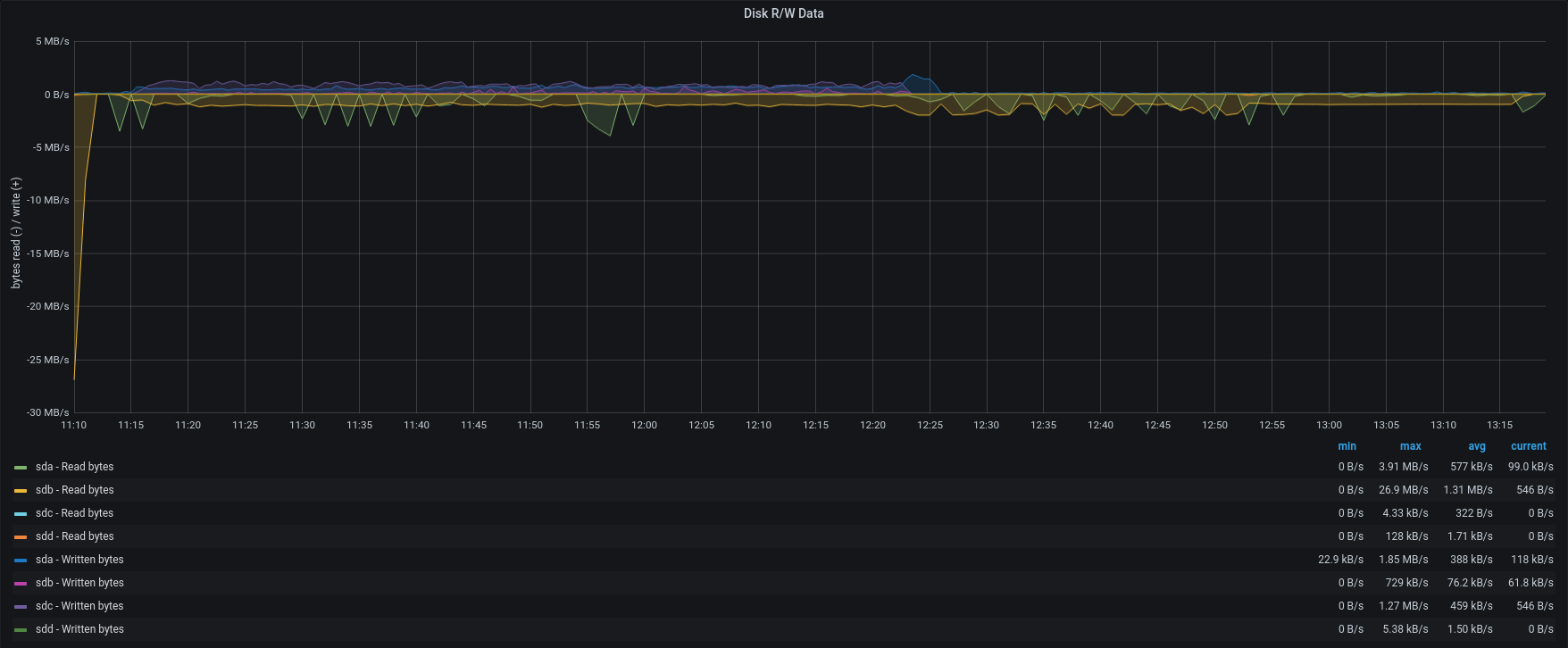 |
| Messages | 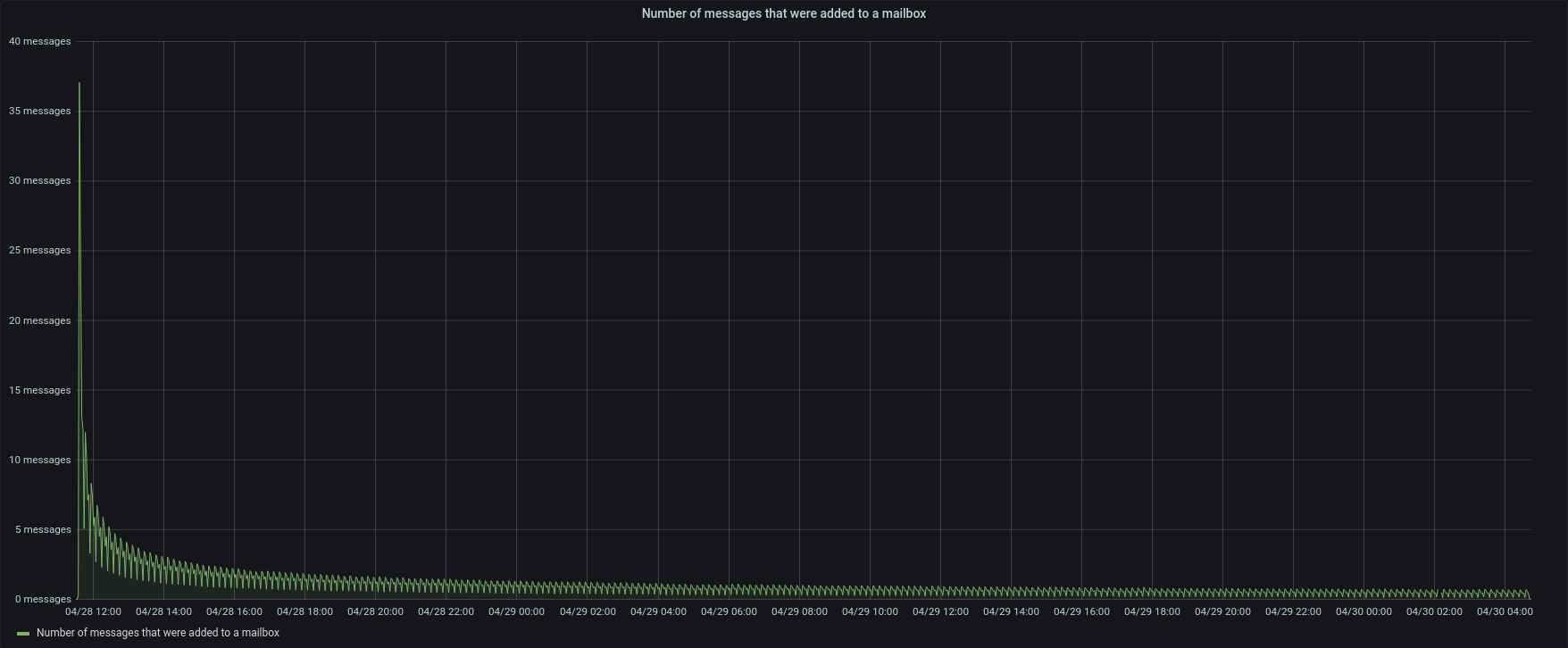 | 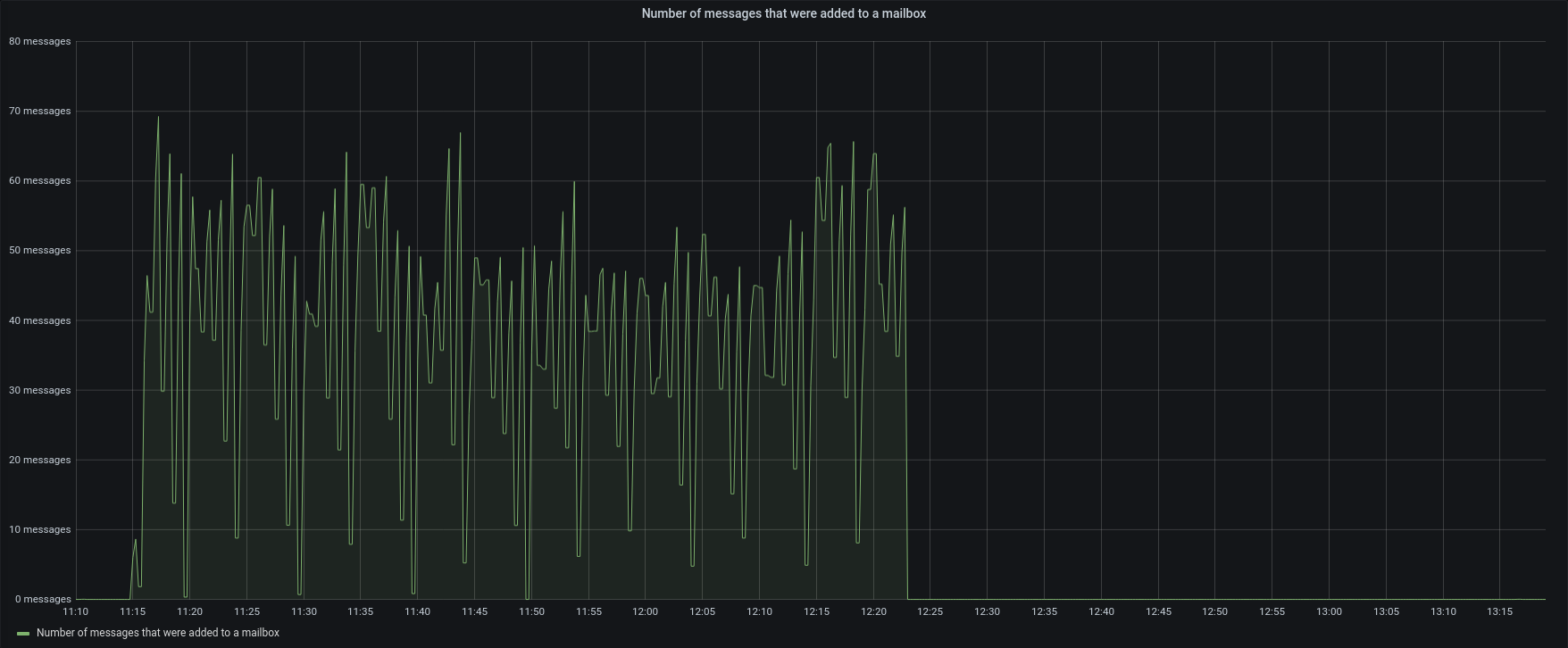 |
This test is a clear view of how we change the process.
Version 3.1.10 used lower CPU, lower disk i/o and tried to add a small number of items for each concurrent account.
Version 3.1.11 reads backup data as fast as possible, adding clusters of messages as quickly as the server can, using all the available memory.
As we can see, the bottleneck is in the IOPS of the Backup-to-restore mount point.
The test suite was completed in 2h 1m 47s against the 41h 6m 26s of the previous version.
About 20time faster, even if the 3.1.10 was slow down a bit by nightly smart scan and other tasks scheduled.
Test2 – External Restore whole domain
For this test we remove all the caps, in order give storage maximum performace.
| 3.1.11 | |
| Operation_id | 1f8718dd-4ca6-4195-9dbd-ba7f2b341b2b |
| Elapsed | 11 hours, 55 minutes, 19 seconds |
| Accounts | 111 |
| Items | 15303444 |
| Items/Sec | 356.565716815396 |
| CPU Stats | 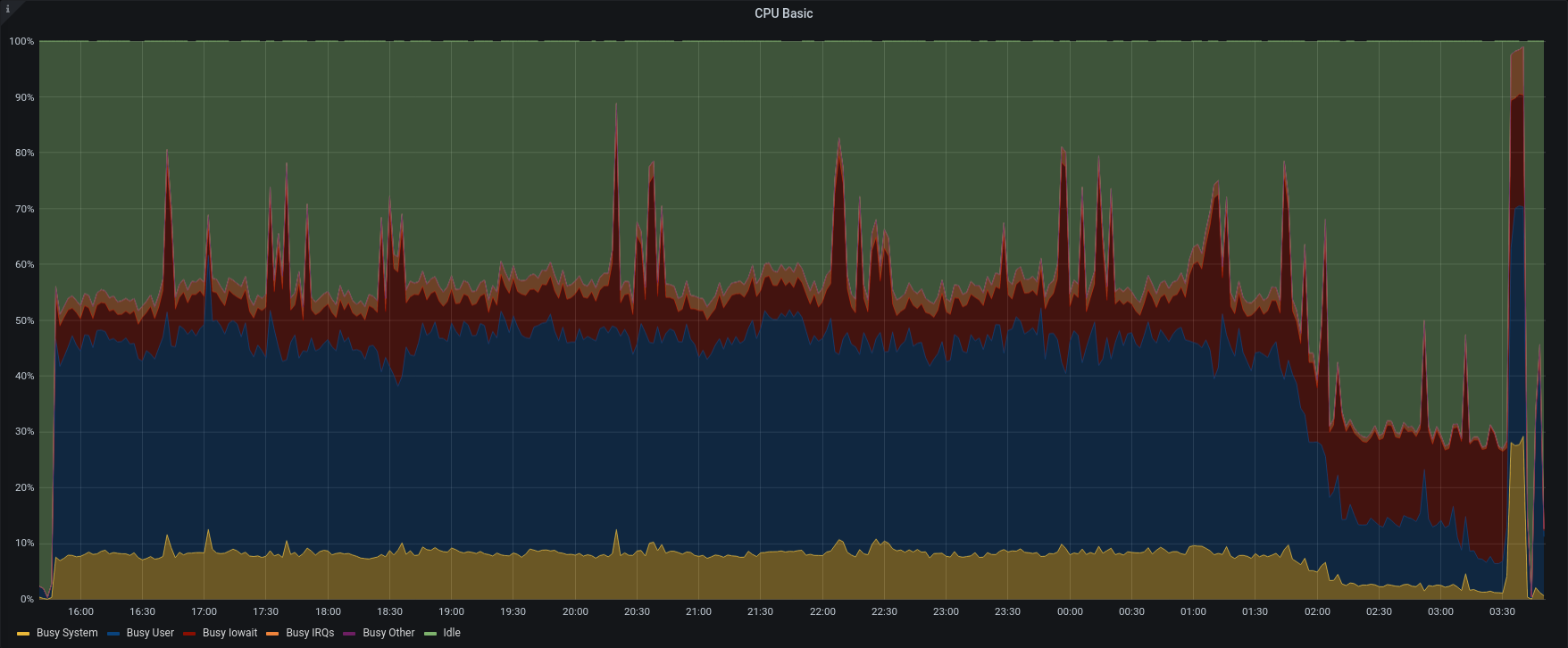 |
| Memory | 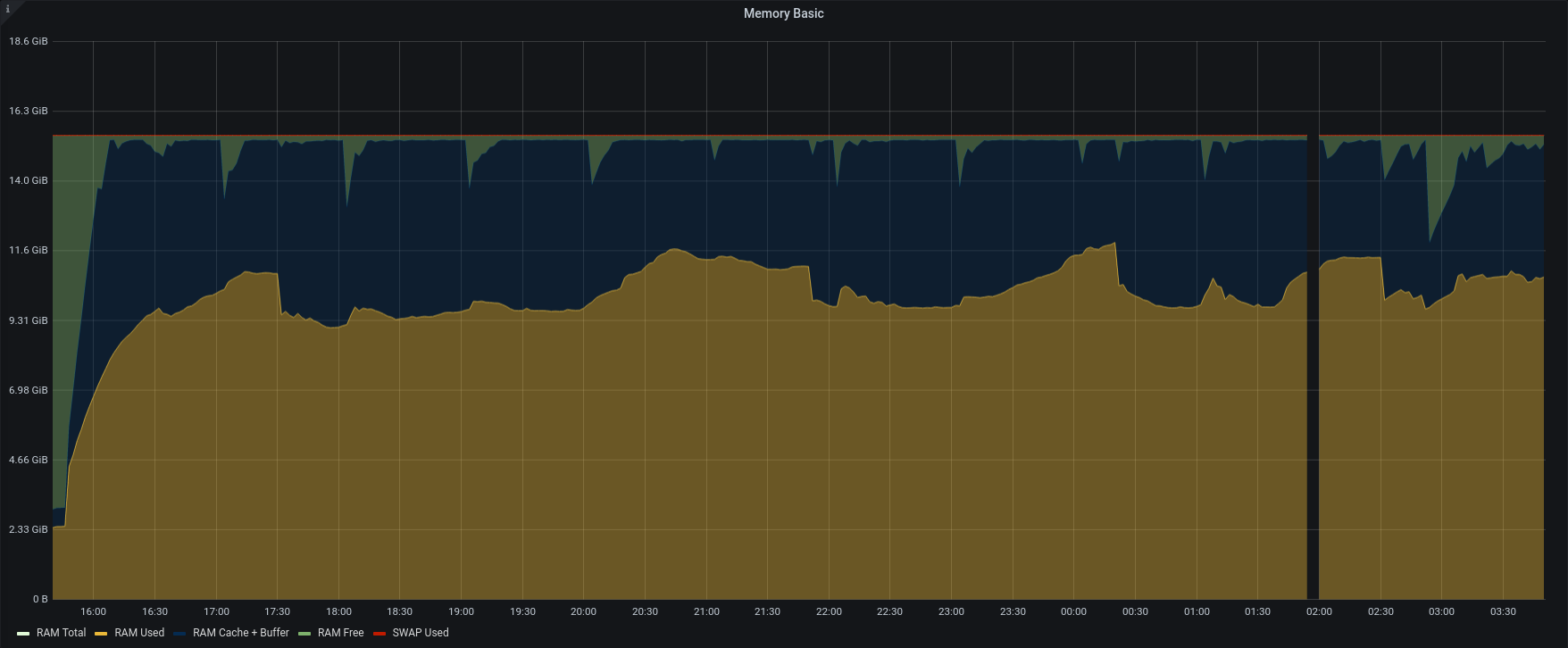 |
| IOPS | 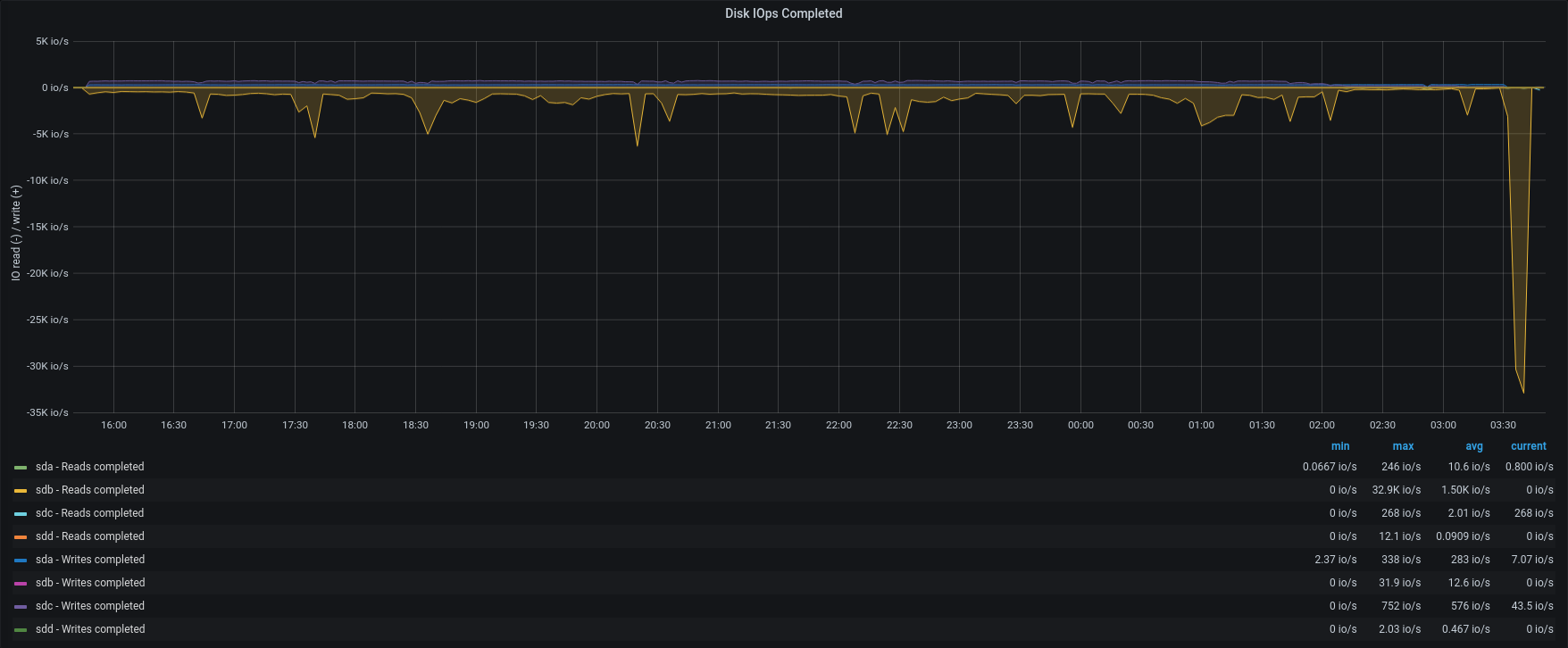 |
| Disk R/W | 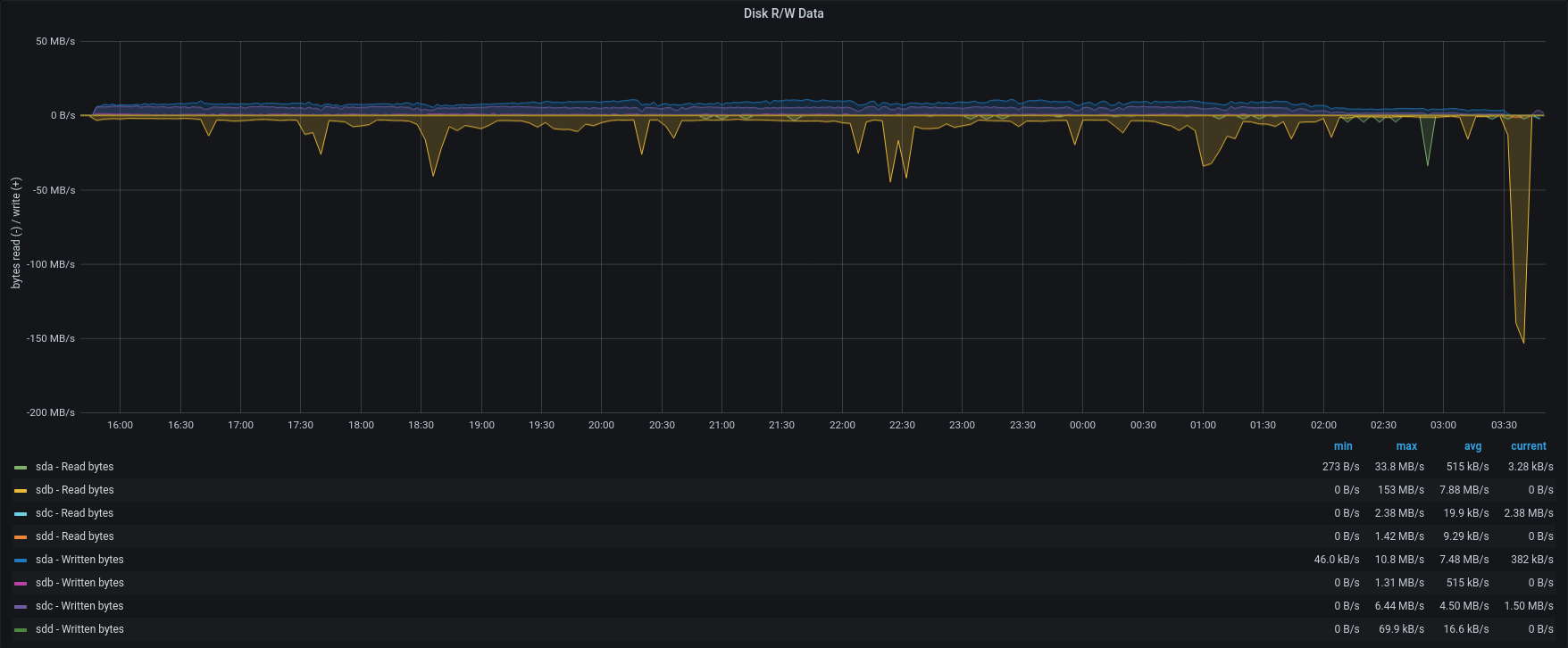 |
| Messages | 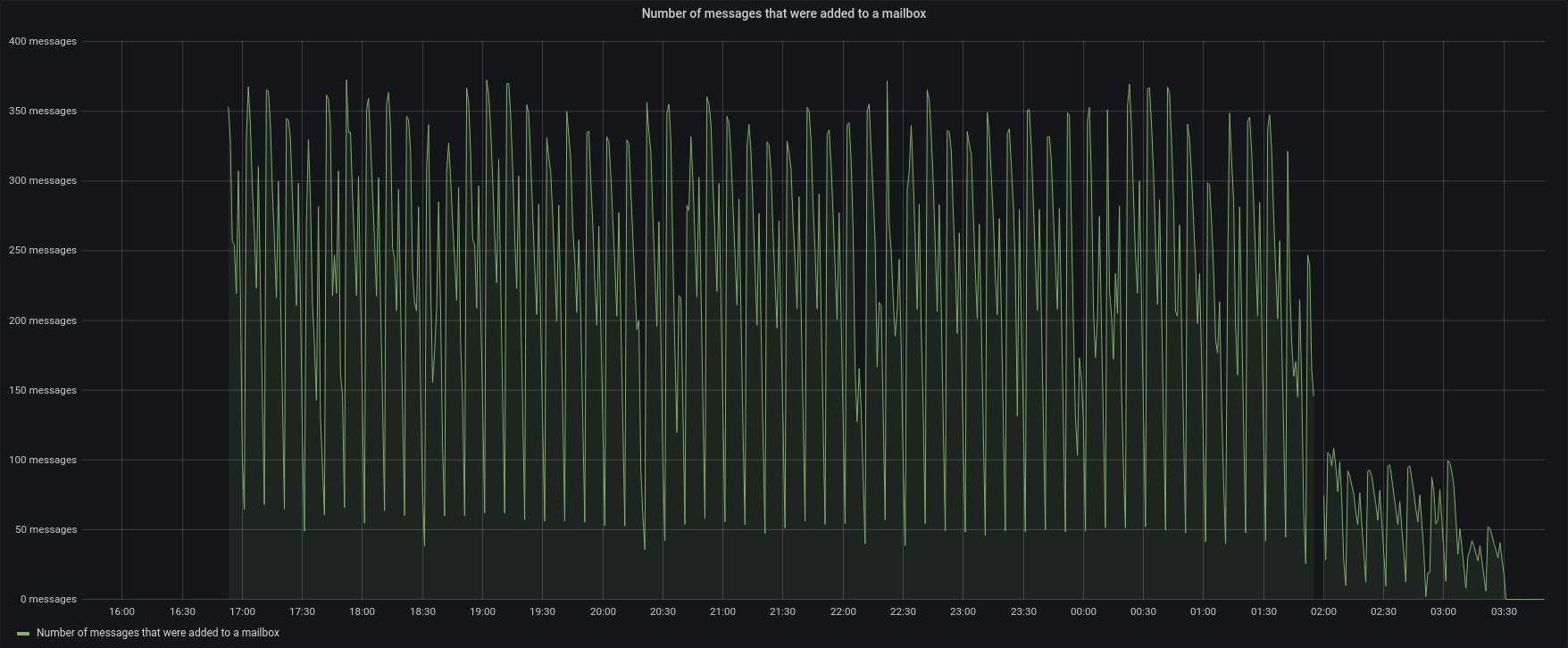 |
Version 3.1.10 wasn’t able to complete the test within 48 hours, the time limit of the test case. All the accounts were provisioned, but after 48 hours, accounts from groups A and B are still ongoing.
Version 3.1.11 completed the entire restore in less than 12hours, with an average of 1200 IOPS reading from the source backup and 600 IOPS writing to the active backup path.
Removing the disk caps, stats jumped from 37 items/sec up to 356 item/sec (x10), according to the IOPS gain (from 200 to 1800).
However looking at the stats, you can see that the last 15minutes were CPU intensive because the backup has to rebuild all the shares for the restored accounts during this stage.
Test3 – External Restore single account from group A and B
| Mailbox Group A | Mailbox Group B | |
| Operation_id | 31b52bf0-8796-4be2-b1cd-4f8376c697e8 | f7fe0bfa-792b-4267-bfad-9f0b64199ca3 |
| Elapsed | 4 hours, 19 minutes | 21 minutes, 6 seconds |
| Accounts | 1 | 1 |
| Items | 1436394 | 270378 |
| Items/Sec | 92 | 213 |
| CPU Stats | 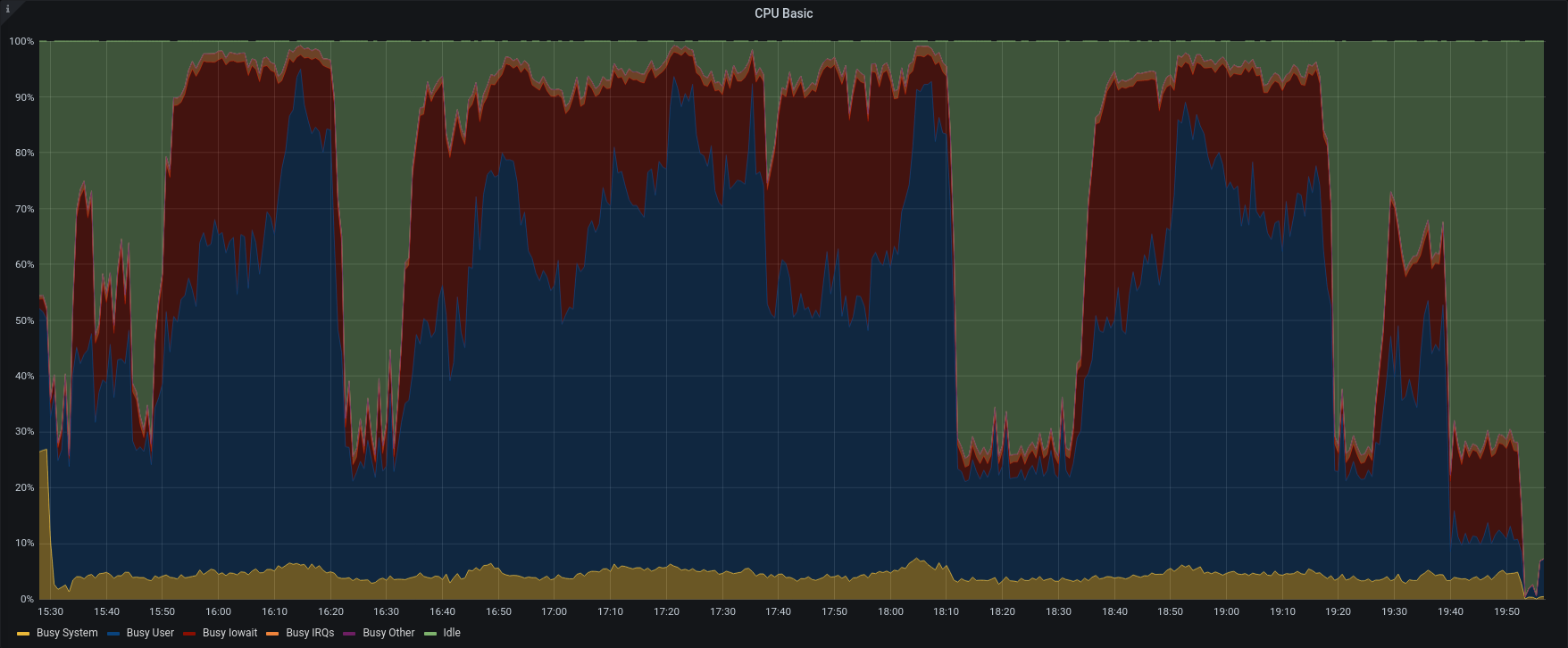 | 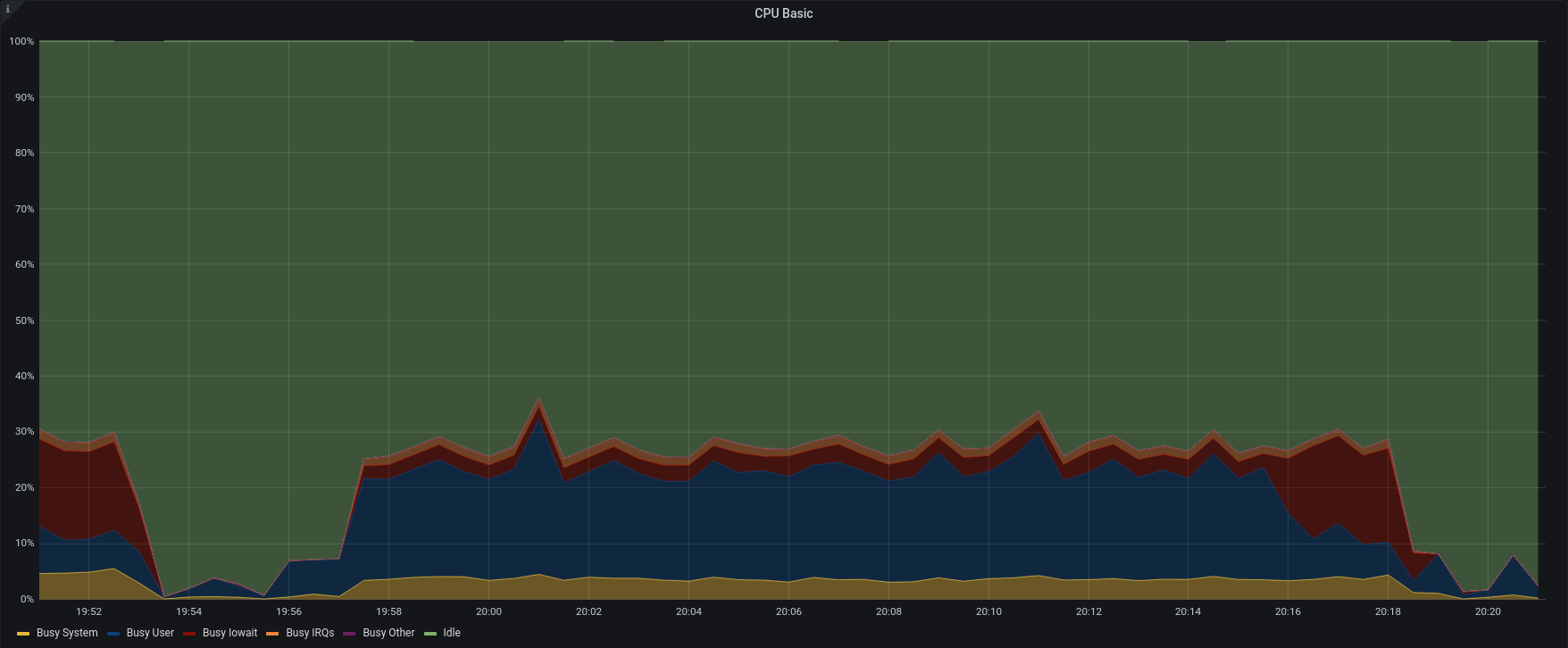 |
| IOPS | 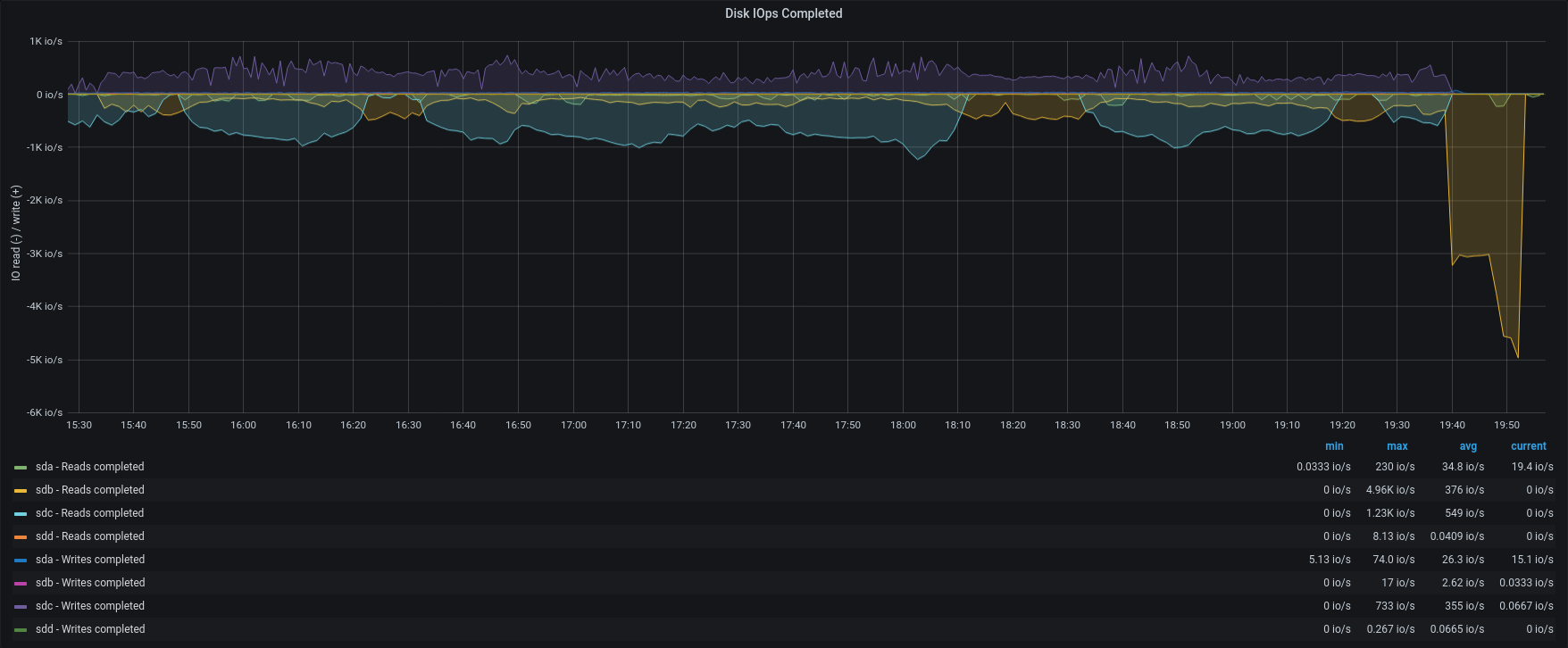 | 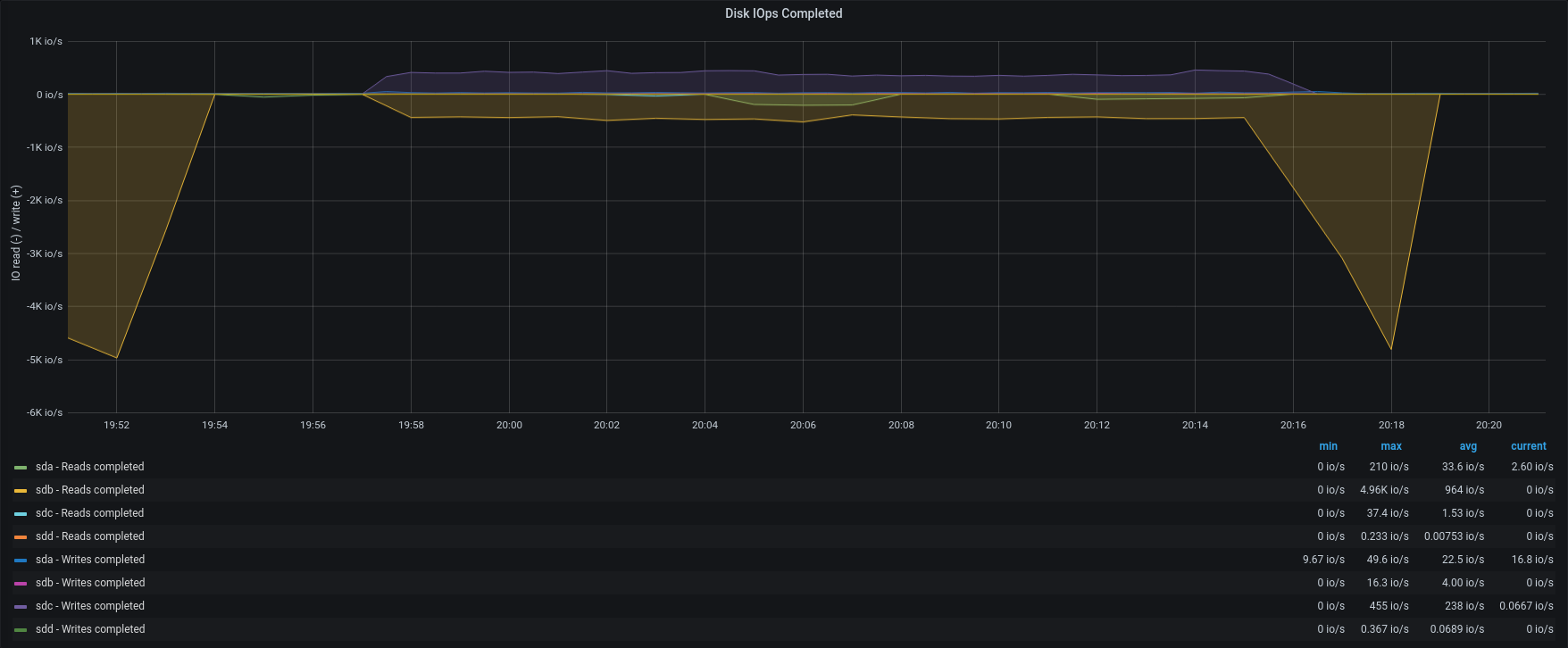 |
| Disk R/W | 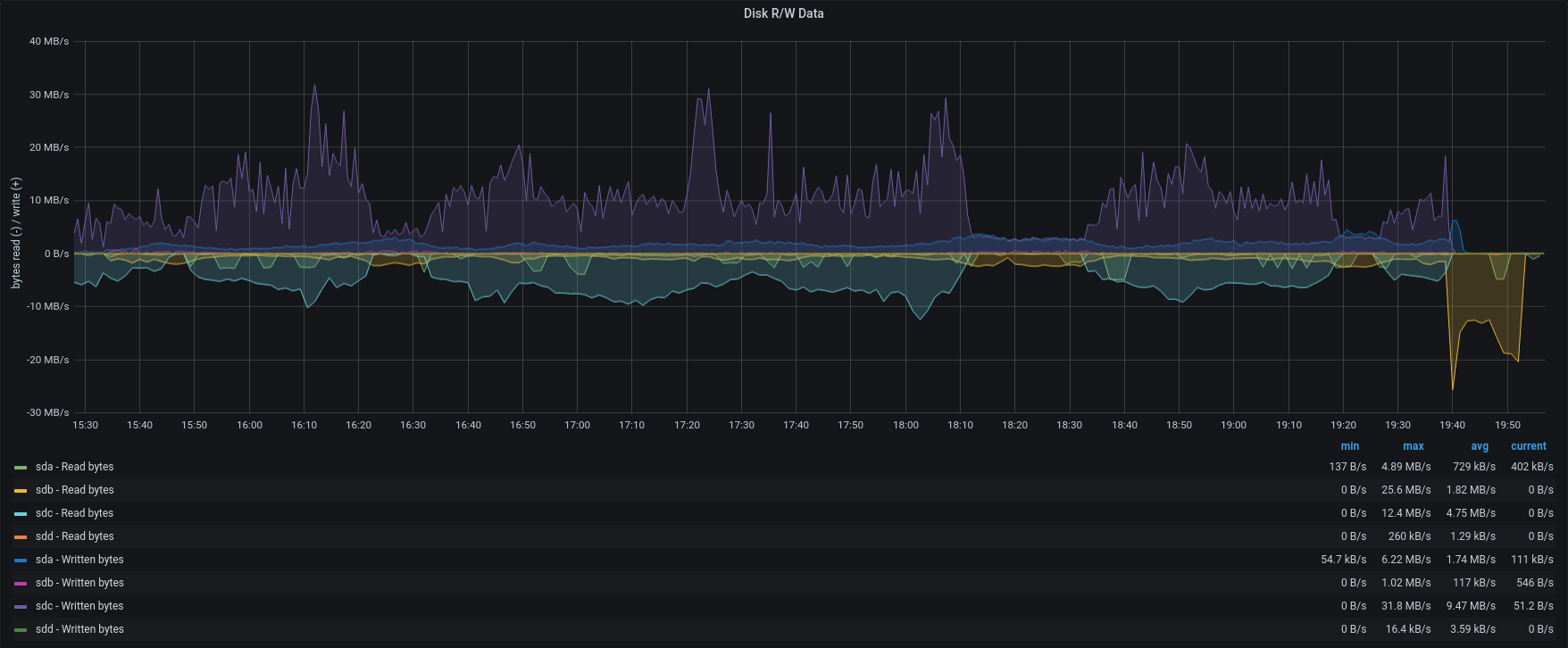 | 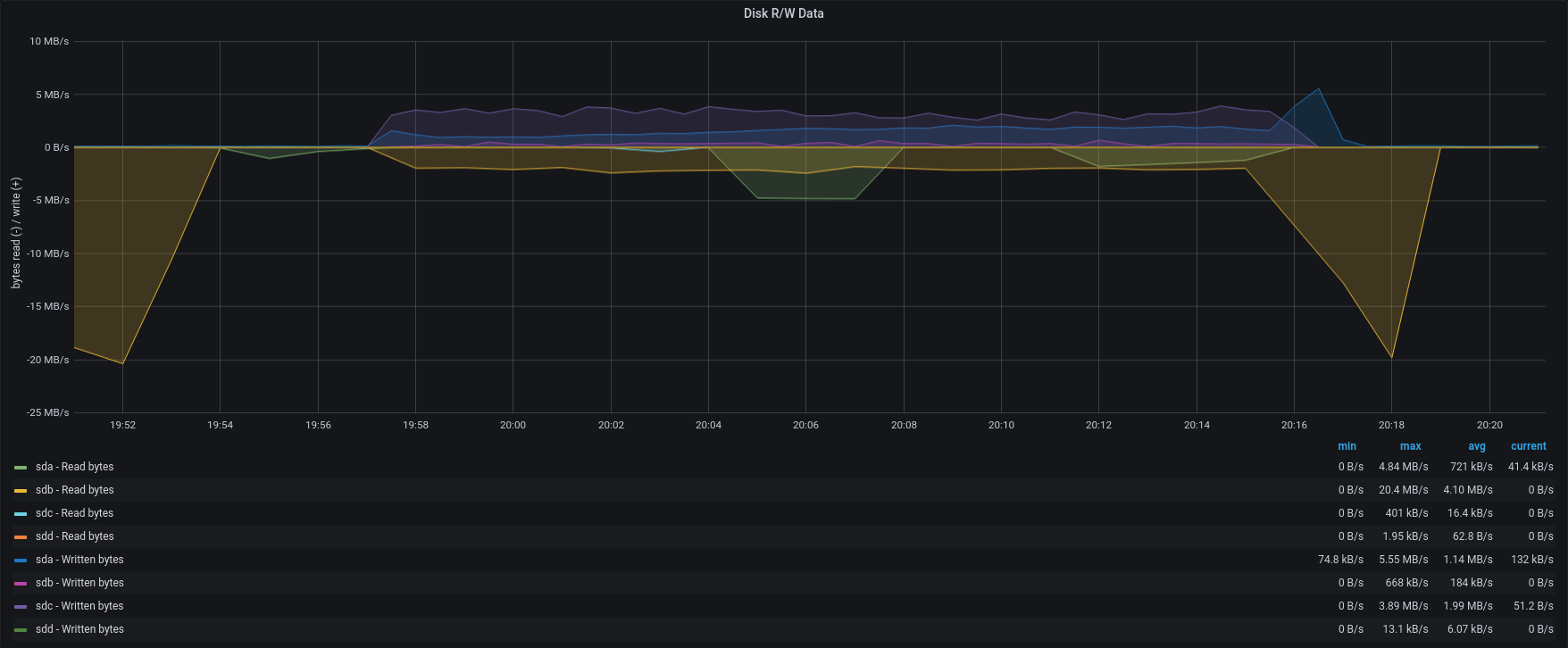 |
| Messages |  | 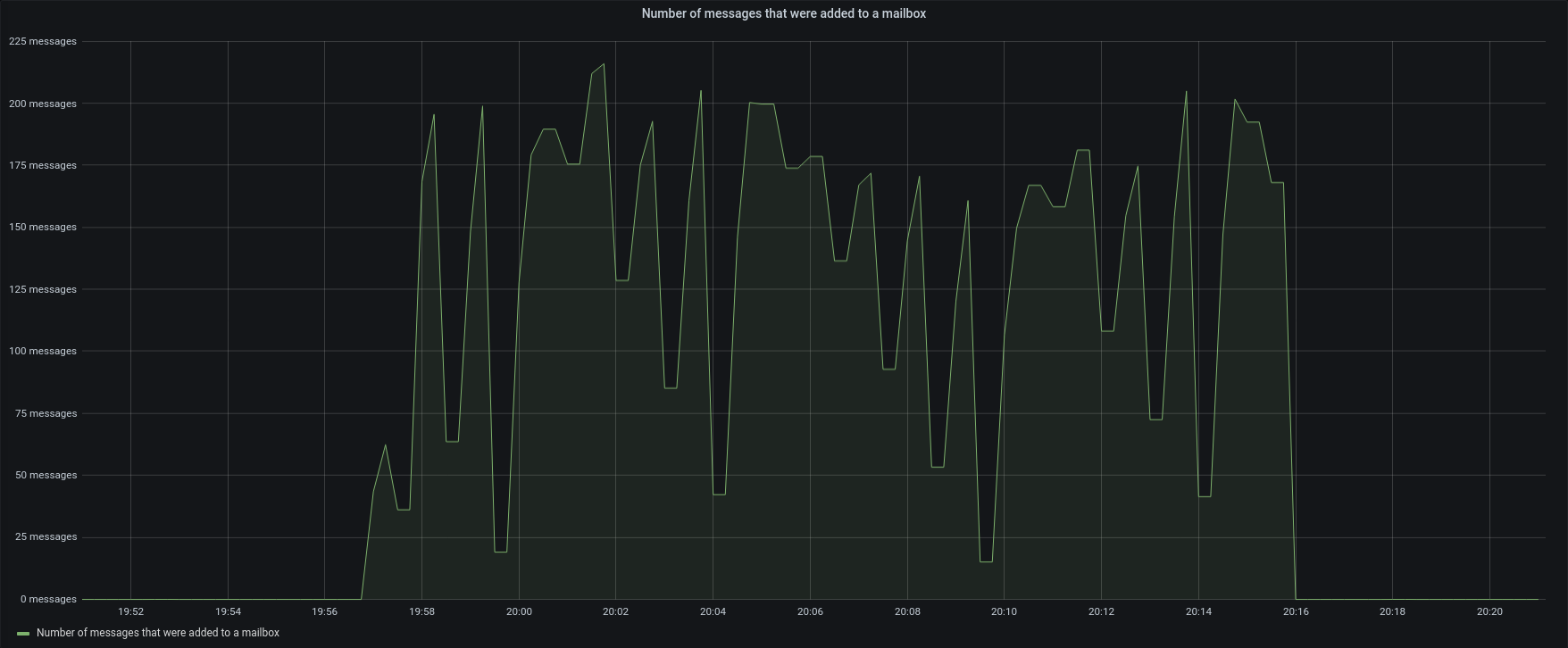 |
To better understand the link between disk performances and backup speed we tried to restore singularly one account from group B and one from group A.
In opposition to the previous test, the item rate dropped to 210 items/sec and 92 items/sec. The frequent GC and the heavy load on the same maysql table, caused intensive CPU usage and slow down the entire process.
We can notice that restoring 1.5M items required less than 5 hours, while the entire domain (about 15 billion) required only 12hours.
Test4 – External Restore 85 accounts – 50 concurrents
| Operation_id | ee19c3d1-f529-4a4d-ab93-cc3c3ac89001 |
| Elapsed | 3 hours, 41 minutes, 24 seconds |
| Accounts | 85 |
| Items | 7913647 |
| Items/Sec | 595 |
| CPU Stats | 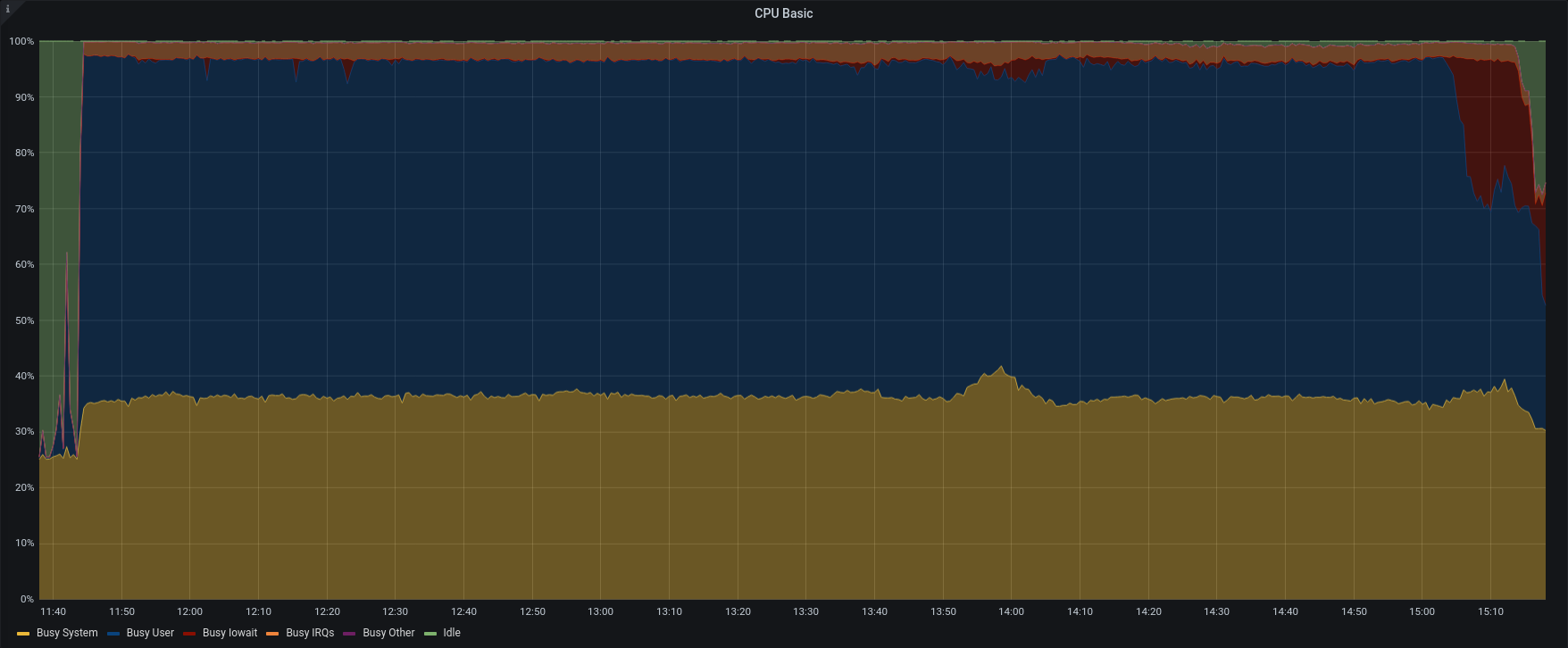 |
| IOPS | 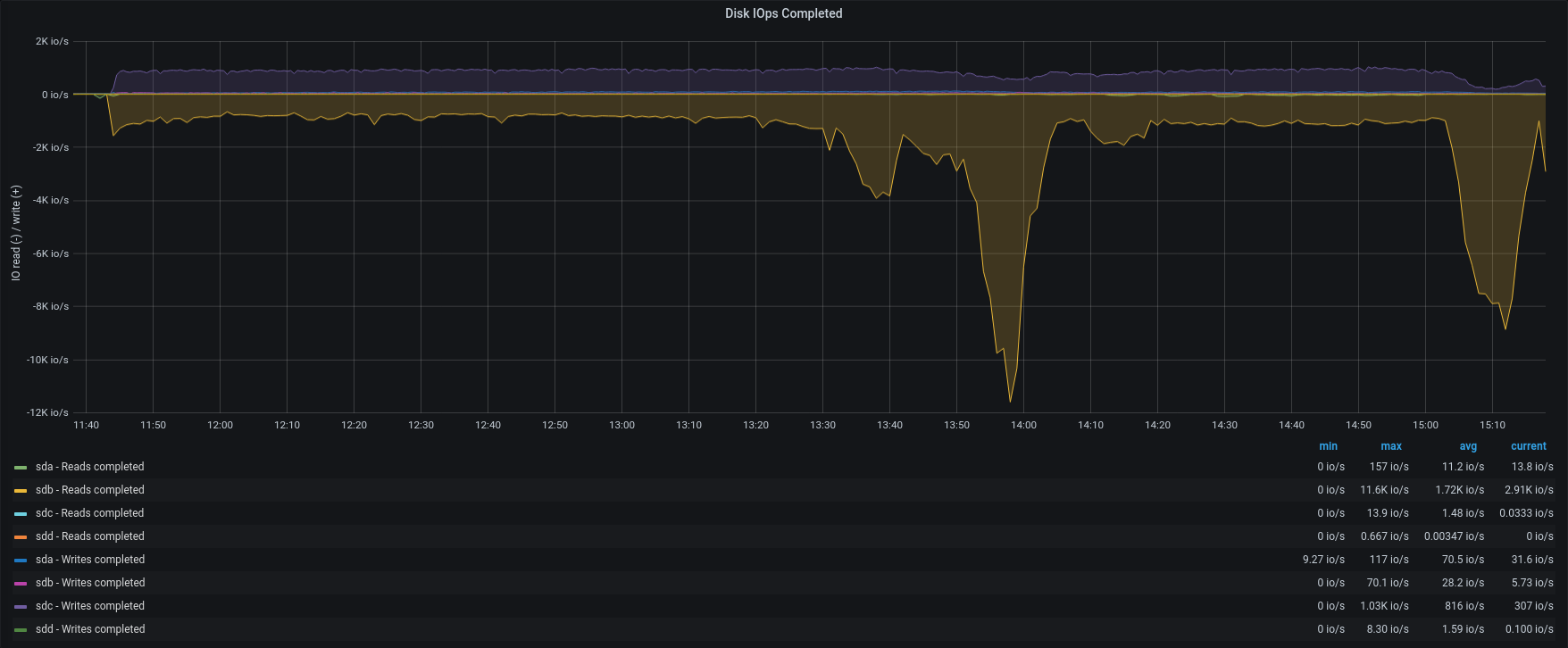 |
| Disk R/W | 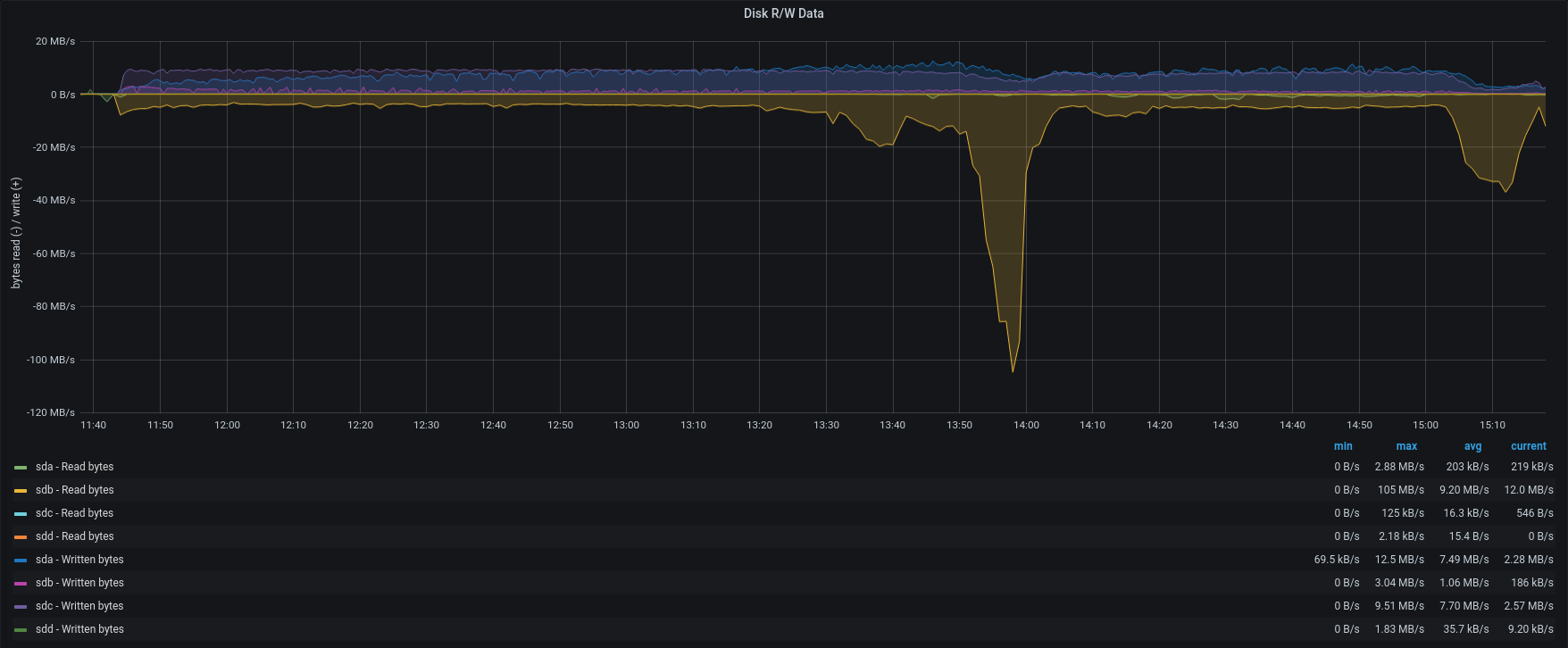 |
| Messages | 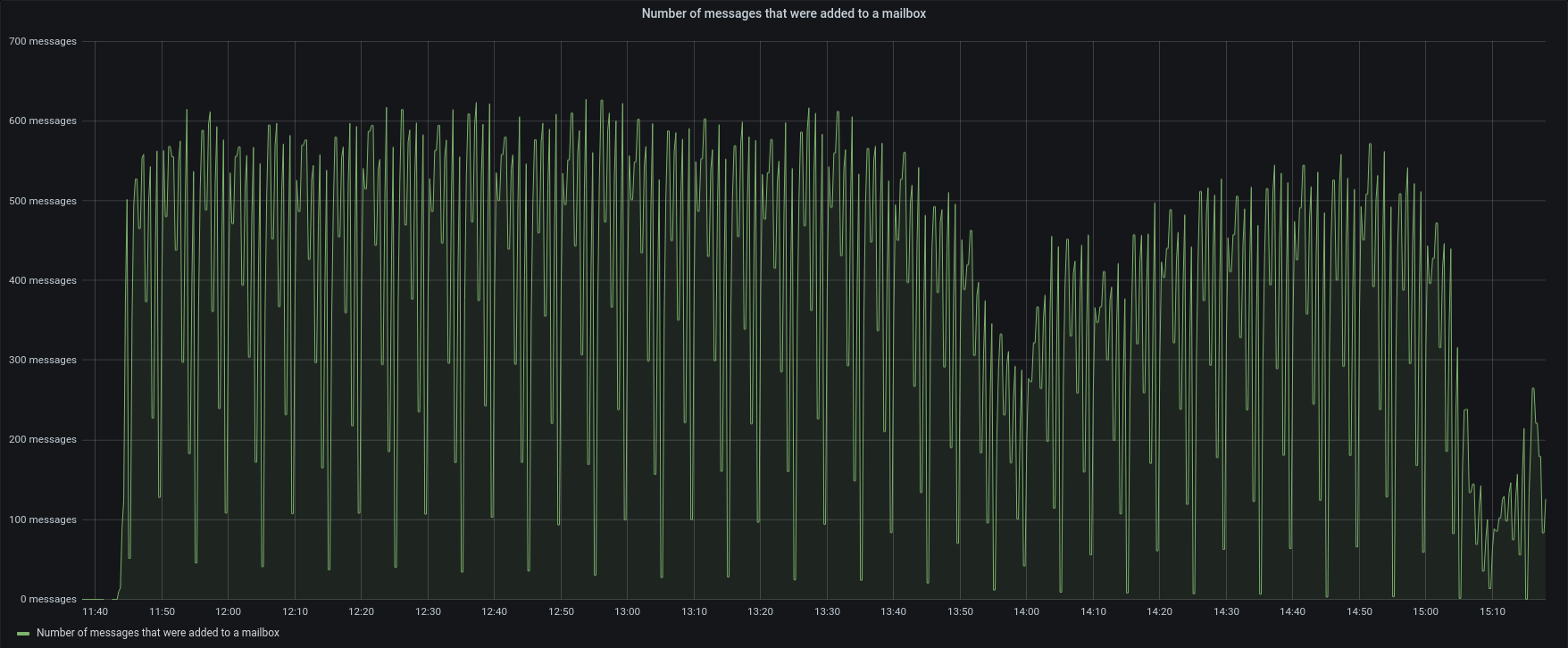 |
To verify our hypothesis we run another import of 85 accounts from group B,C,and D ( 7 billions of items), using 50 concurrents to lead to the limit the restore.
Obviously the average load was higher than before and the SSD provided an average of 1800 IOPS, but the restore was completed in less than 4 hours, with an average of 595 items/sec, the maximum speed we were able to reach!
Additional Cases
We focused all the previous tests on metadata because we know they are the critical factor. But the overall performances are also impacted by the transfer rate or bandwidth available from the blobs.
To complete the tests, we also included an additional tiny case such organized:
- 20 accounts
- more than 1170.000 emails
- 60Gb total storage
We configured the backup using the S3 External Storage. It used around 45GB on S3 and 628MB on the local metadata disk (10% of the logical space).
We carried on the restore process using different scenarios.
Full remote: once downloaded the metadata, the server read the blobs from the remote backup, and it uses remote centralized storage as the primary volume.
Half remote: once downloaded both metadata and blobs, the server read the data locally, and it uses remote centralized storage as the primary volume.
Local: once downloaded both metadata and blobs, the server read the data locally, and it uses local storage as the primary volume.
Full remote:
| 3.1.10 | 3.1.11 | |
|---|---|---|
| OperationId | a3e39cce-f935-49f7-96f0-c095a7868a72 | 9e8e7357-b9c1-423b-9cb3-b5bd0f4d932e |
| Elapsed | 13 hours, 27 minutes, 56 seconds | 11 hours, 2 minutes, 57 seconds |
| CPU |  | 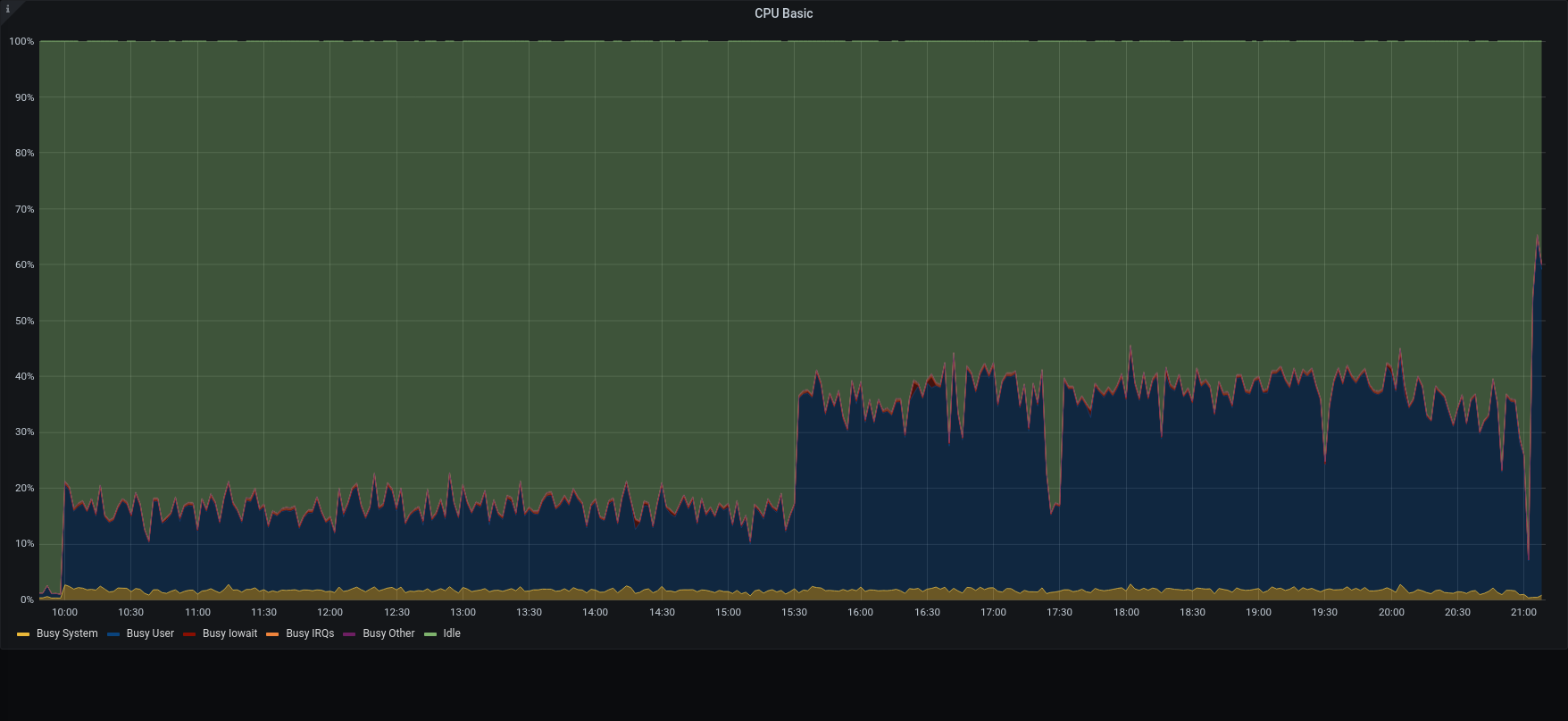 |
| Network | 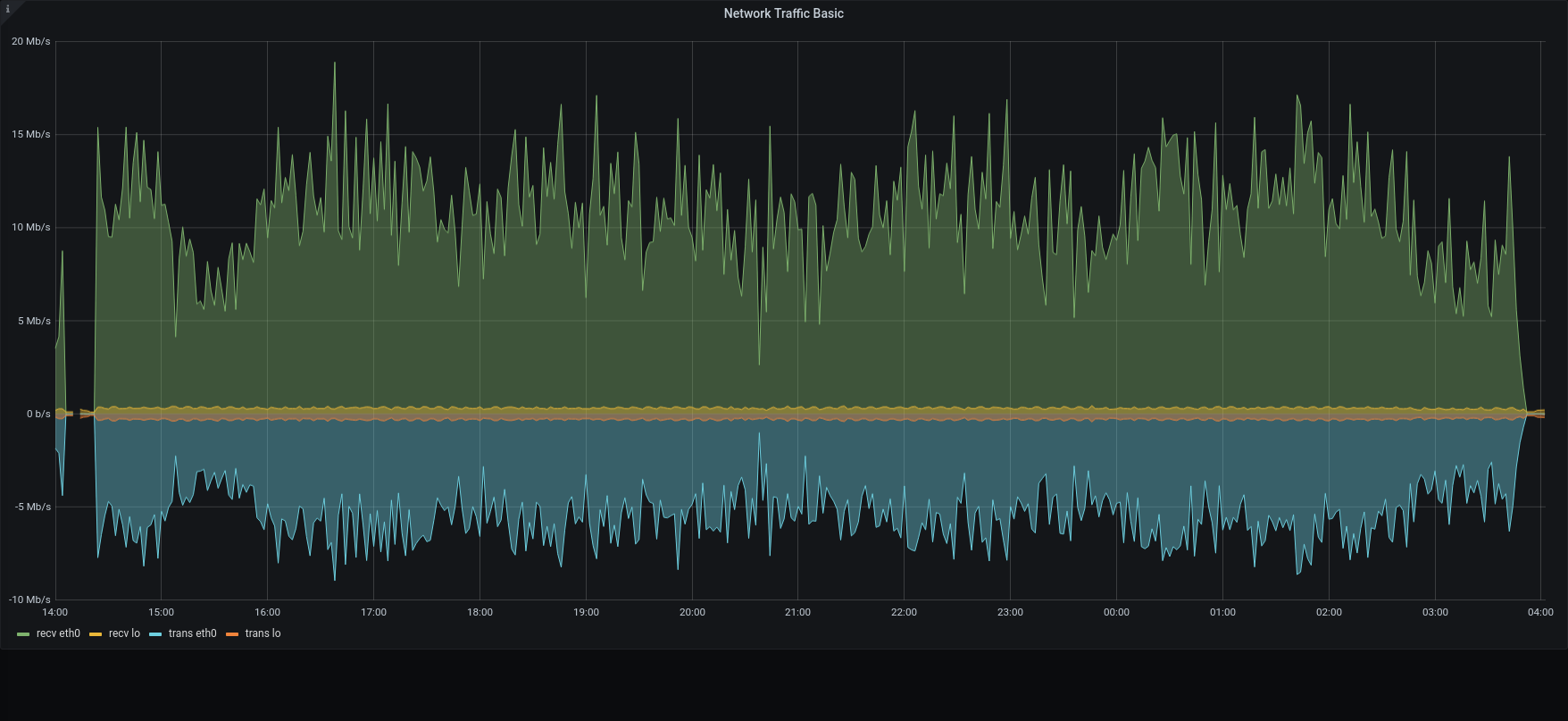 | 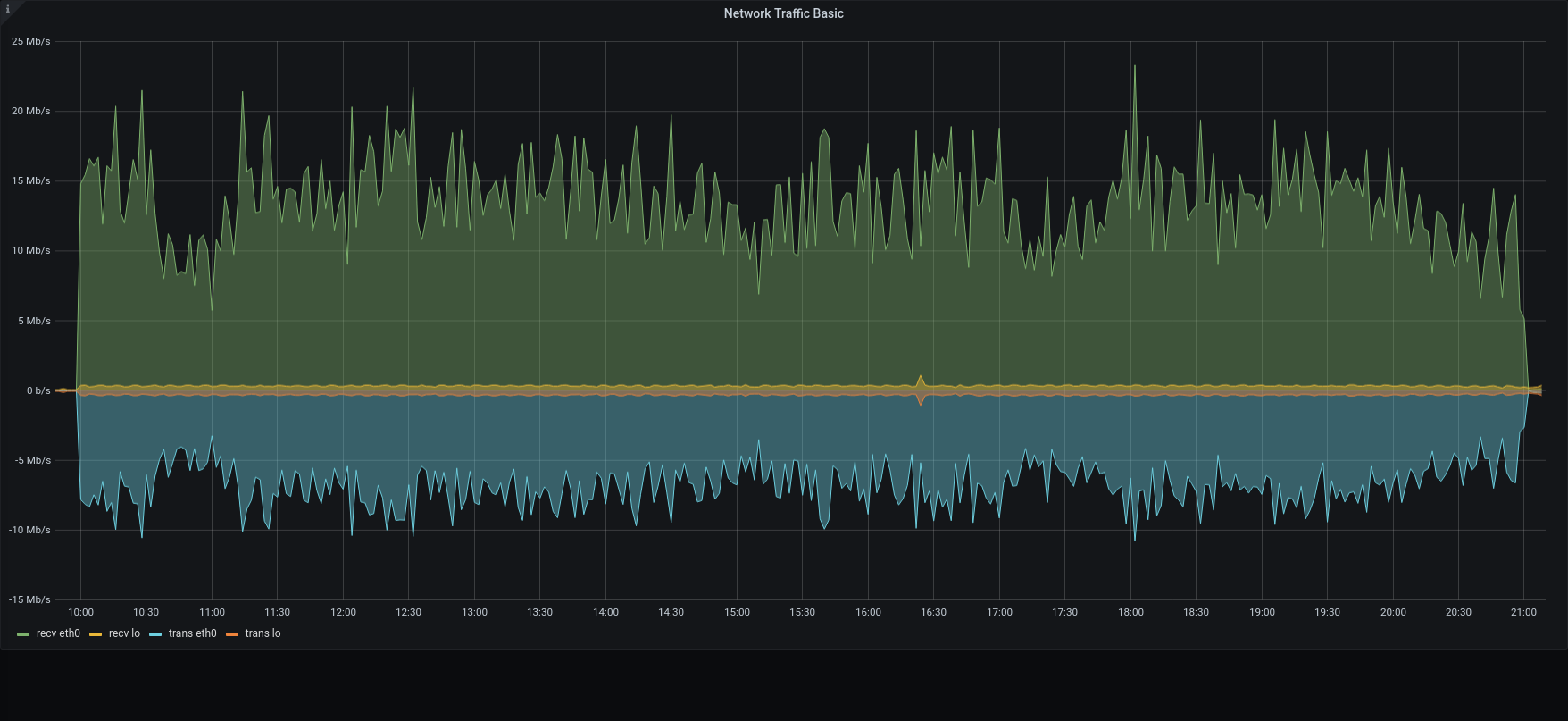 |
| messages | 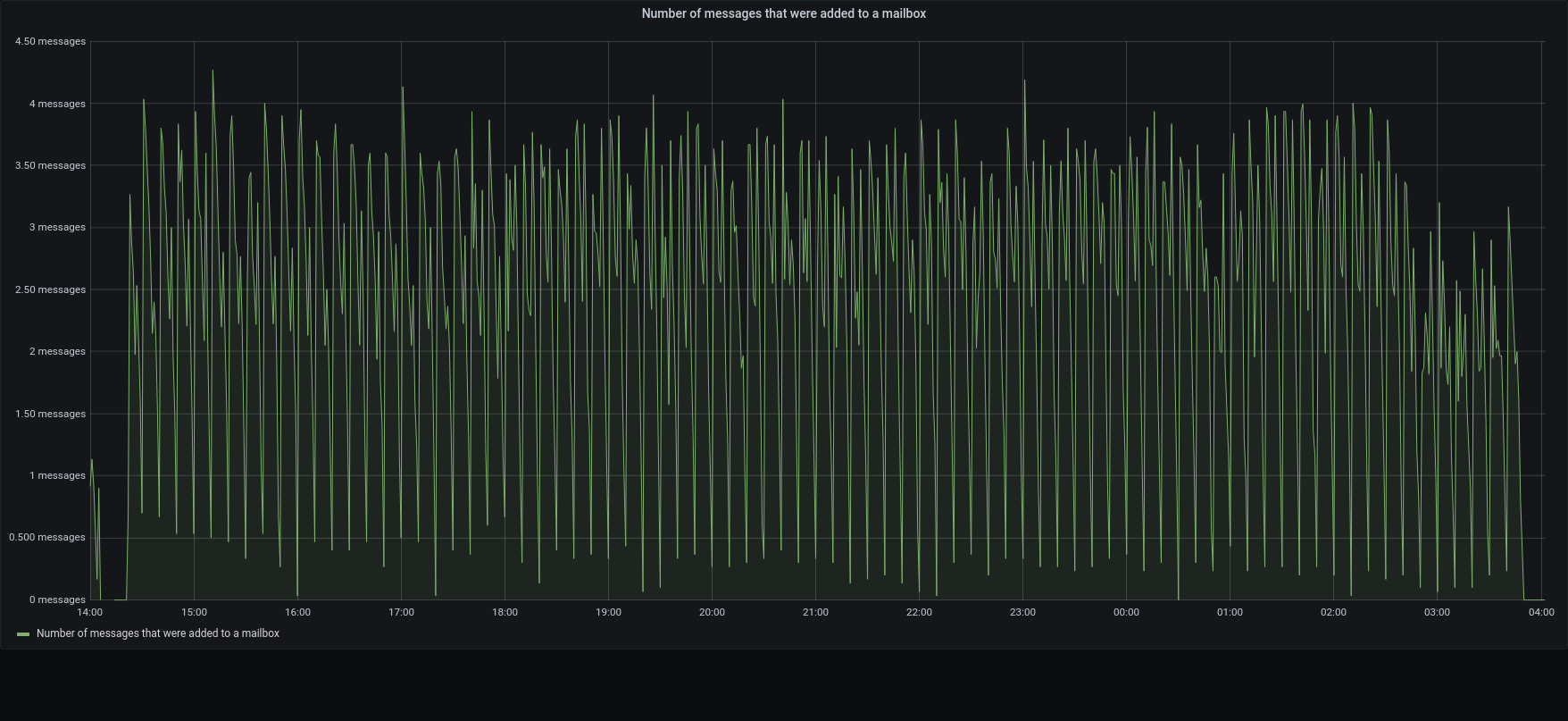 | 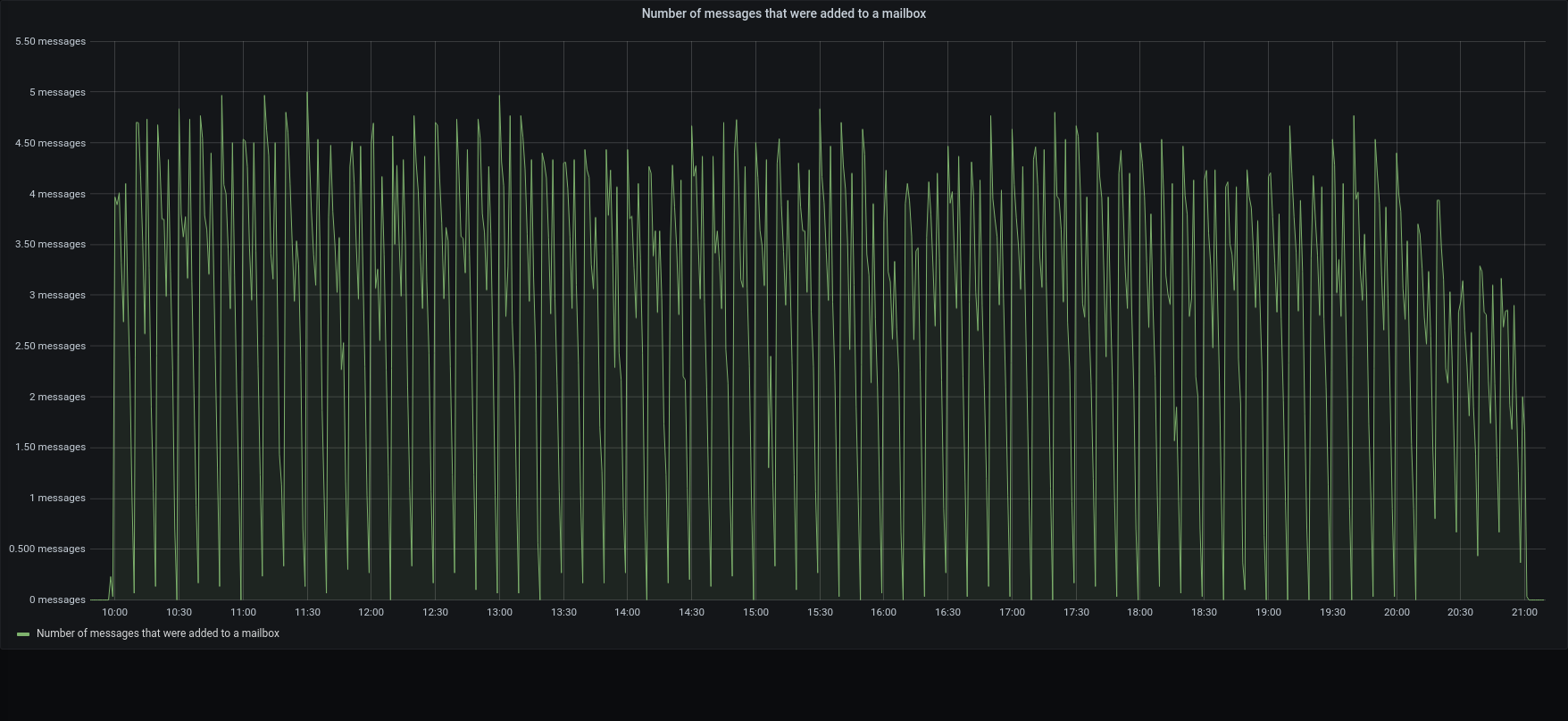 |
The restore was executed reading metadata from the local disk , while blobs was read directly from the S3. Also mariaDB was local on the SSD, while blobs were written on the Centralized S3 Storage
Within this configuration, all the metadata operation was done locally, while the blobs were written and retrieved using an internet connection.
3.1.1 was x1.2 faster than previous version in managing the metadata, but the transfer speed had a huge impact on the overall duration.
Half remote:
| 3.1.10 | 3.1.11 | |
|---|---|---|
| OperationId | 19f0aa9b-0986-4bac-b7e7-358c43ace1cf | e63398d8-050c-44e1-8f50-b1373d7a3b6c |
| Duration | 12 hours, 22 minutes | 9 hours, 22 minutes, 56 seconds |
| CPU |  |  |
| Network | 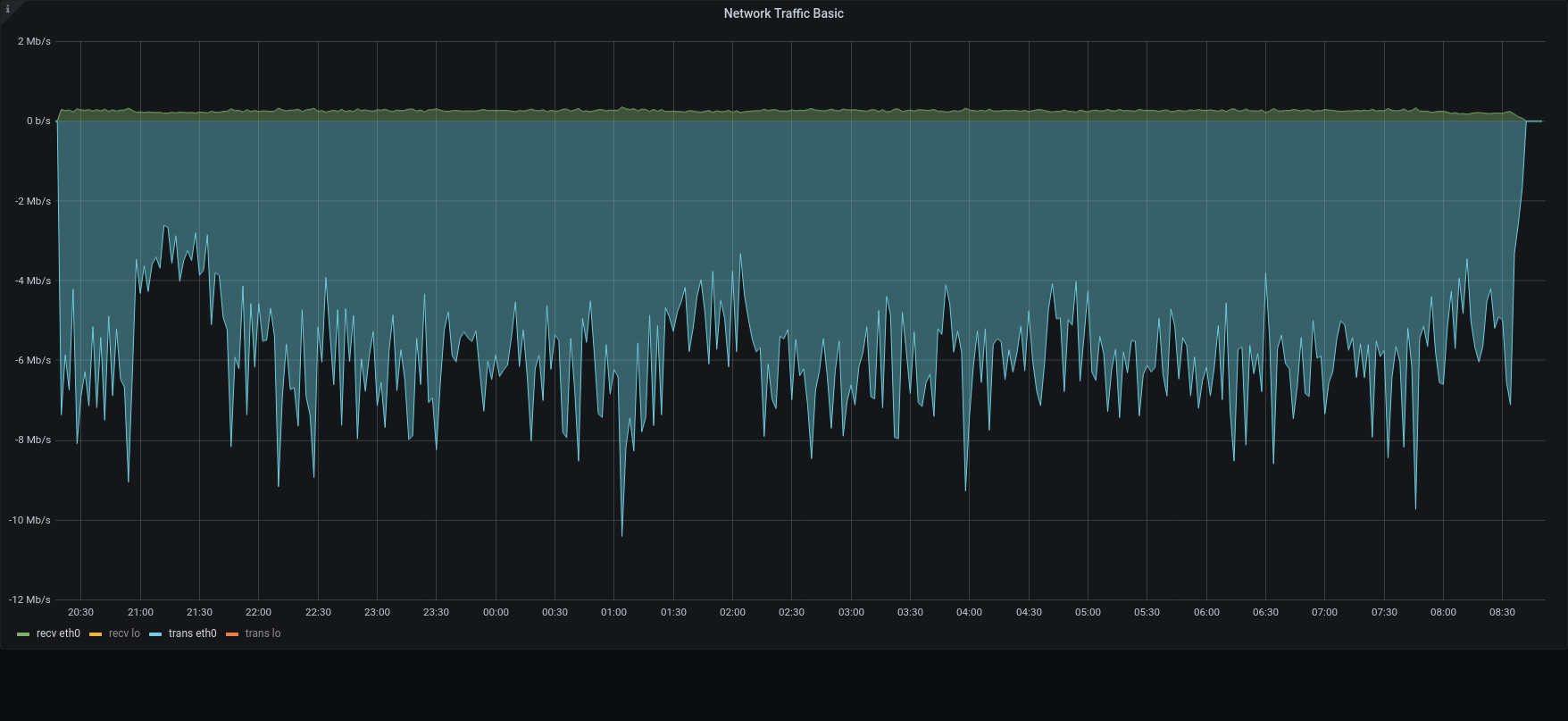 |  |
| messages | 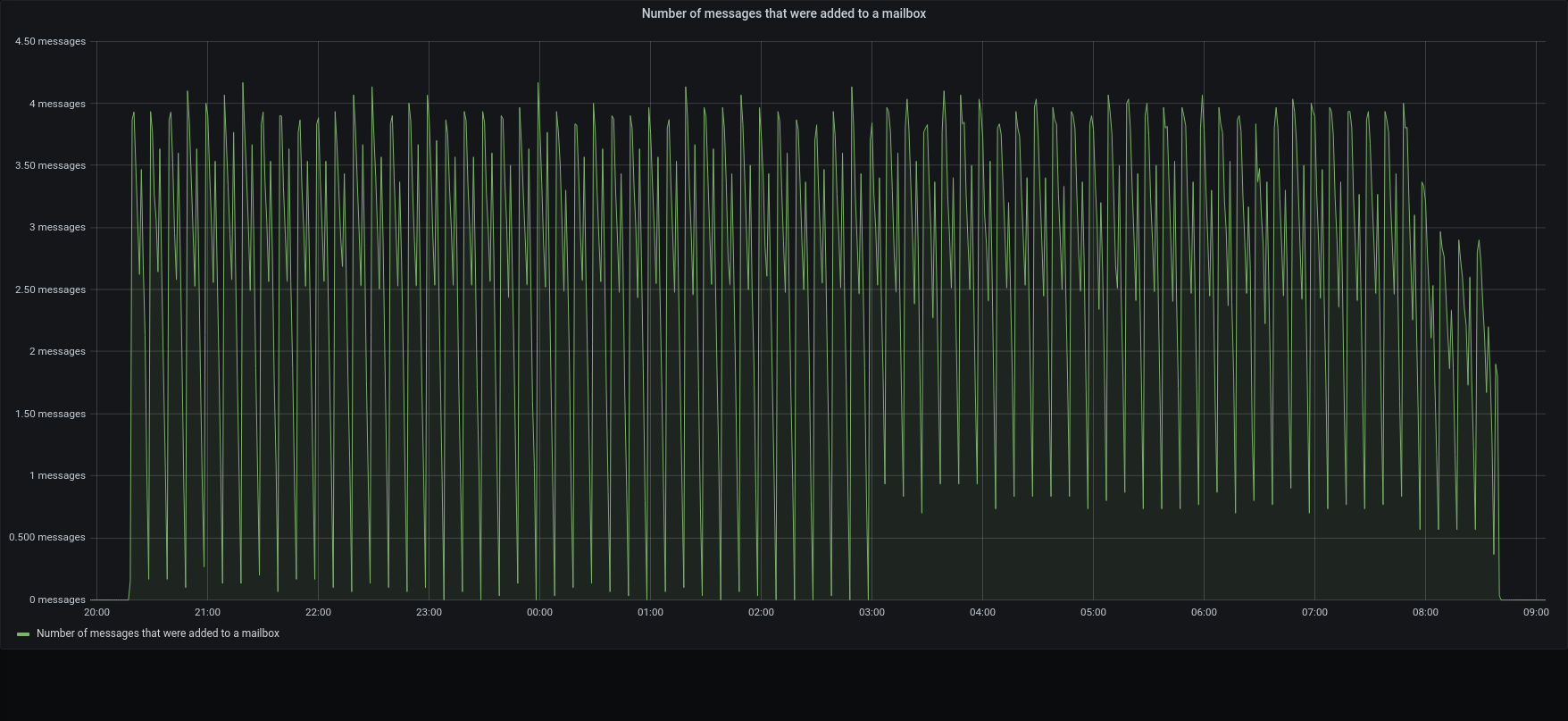 | 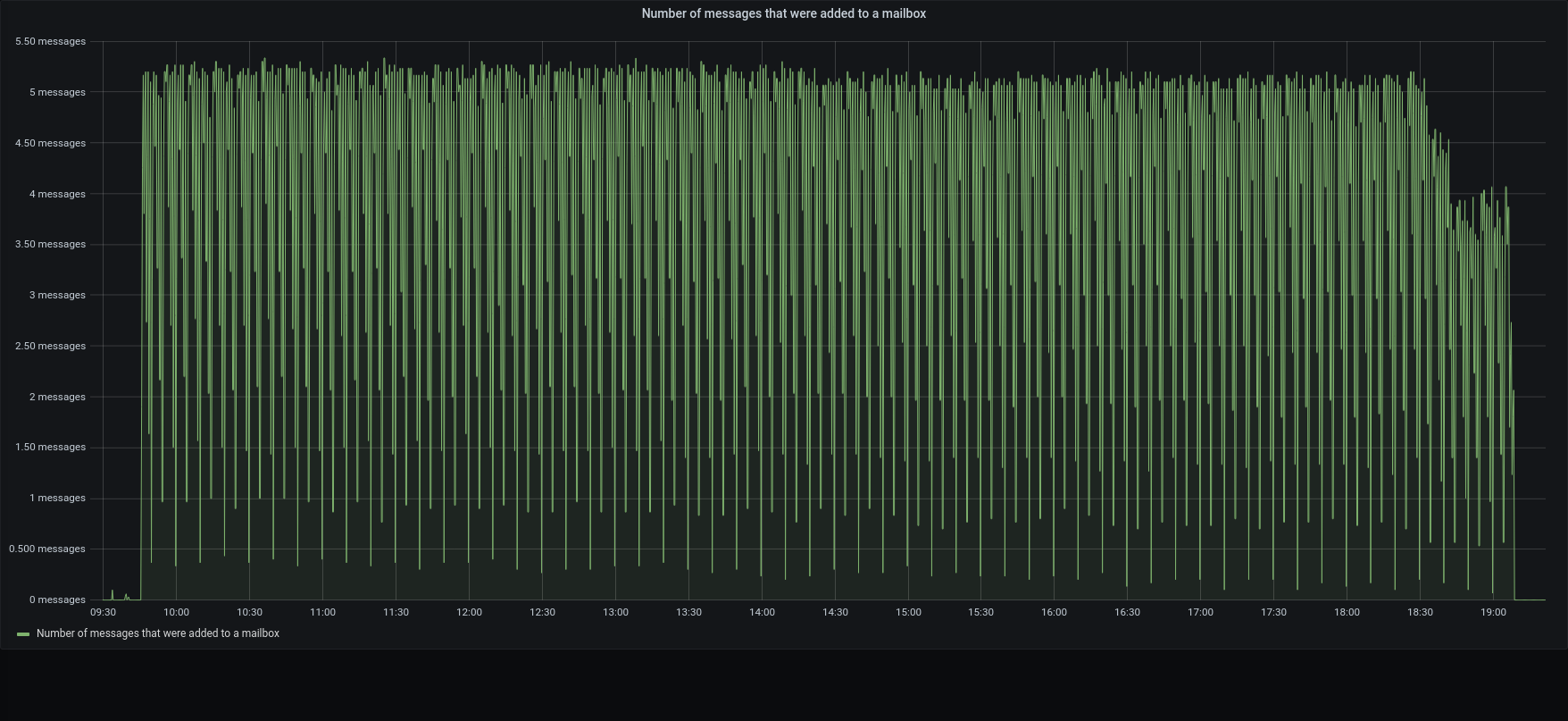 |
The restore was executed reading blobs and metadata from the local disk , such as the backup was locally mounted. Still mariaDB was local on the SSD, instead blobs were written on the Centralized S3 Storage
Within this configuration, all the metadata operation was done locally, while the blobs were written retrieved using an internet connection.
3.1.1 was x1.3 faster than the previous version in managing the metadata, but the transfer speed still had impact on the overall duration.
Local:
| 3.1.10 | 3.1.11 | |
|---|---|---|
| OperationId | 6e4f45fc-6033-4ea7-a70d-530d67bb6424 | a5ceda59-f543-470b-83f1-923c983ad2ee |
| Duration | 3 hours, 15 minutes, 51 seconds | 51 minutes, 26 seconds |
| CPU | 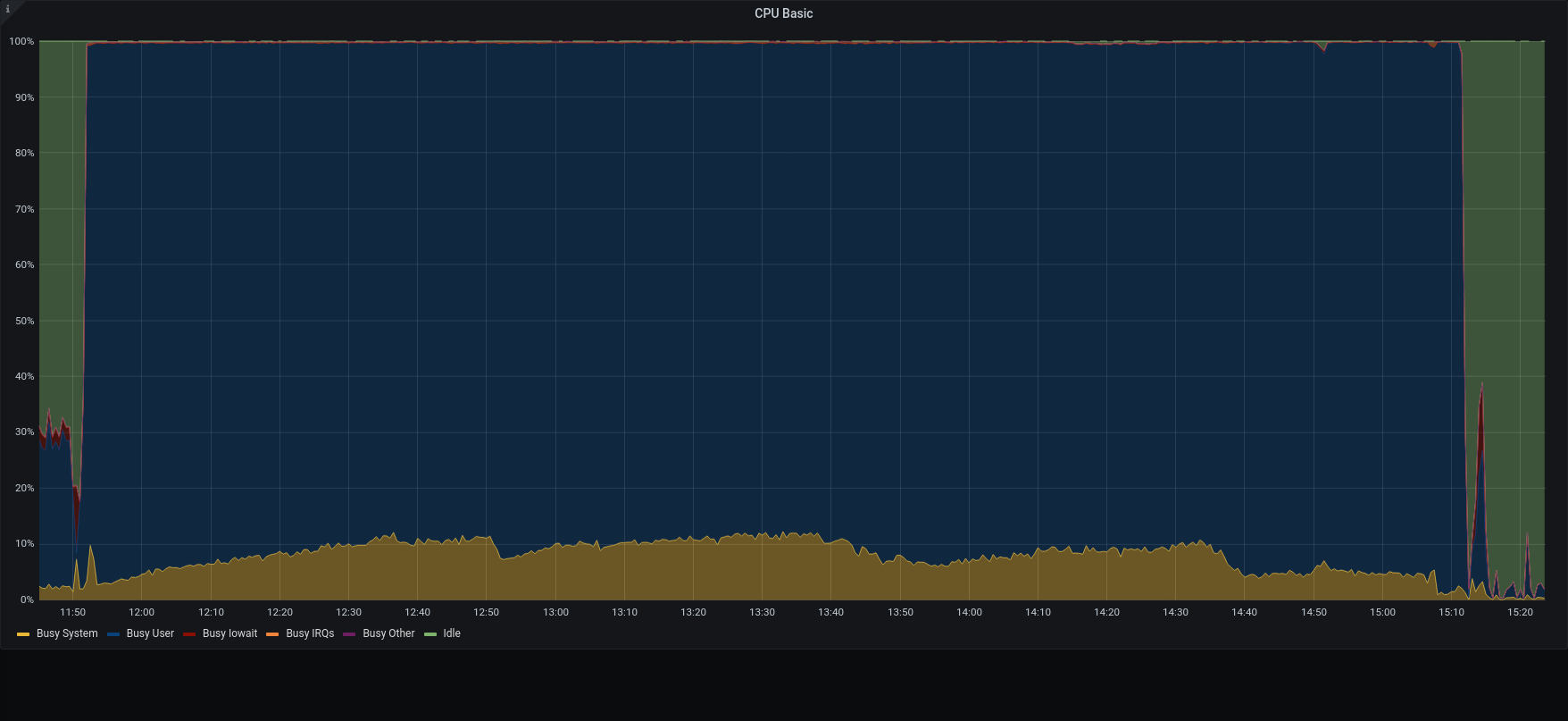 | 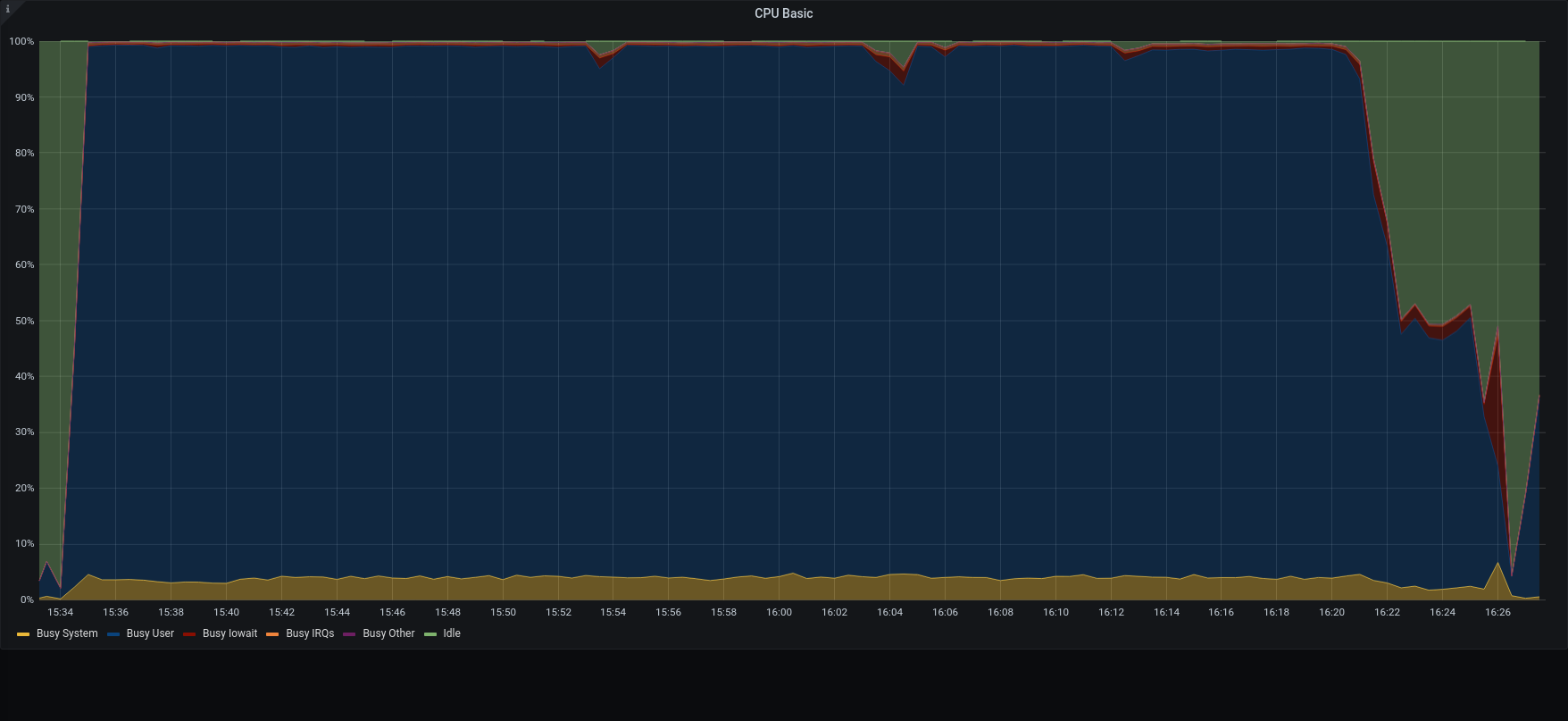 |
| Network | 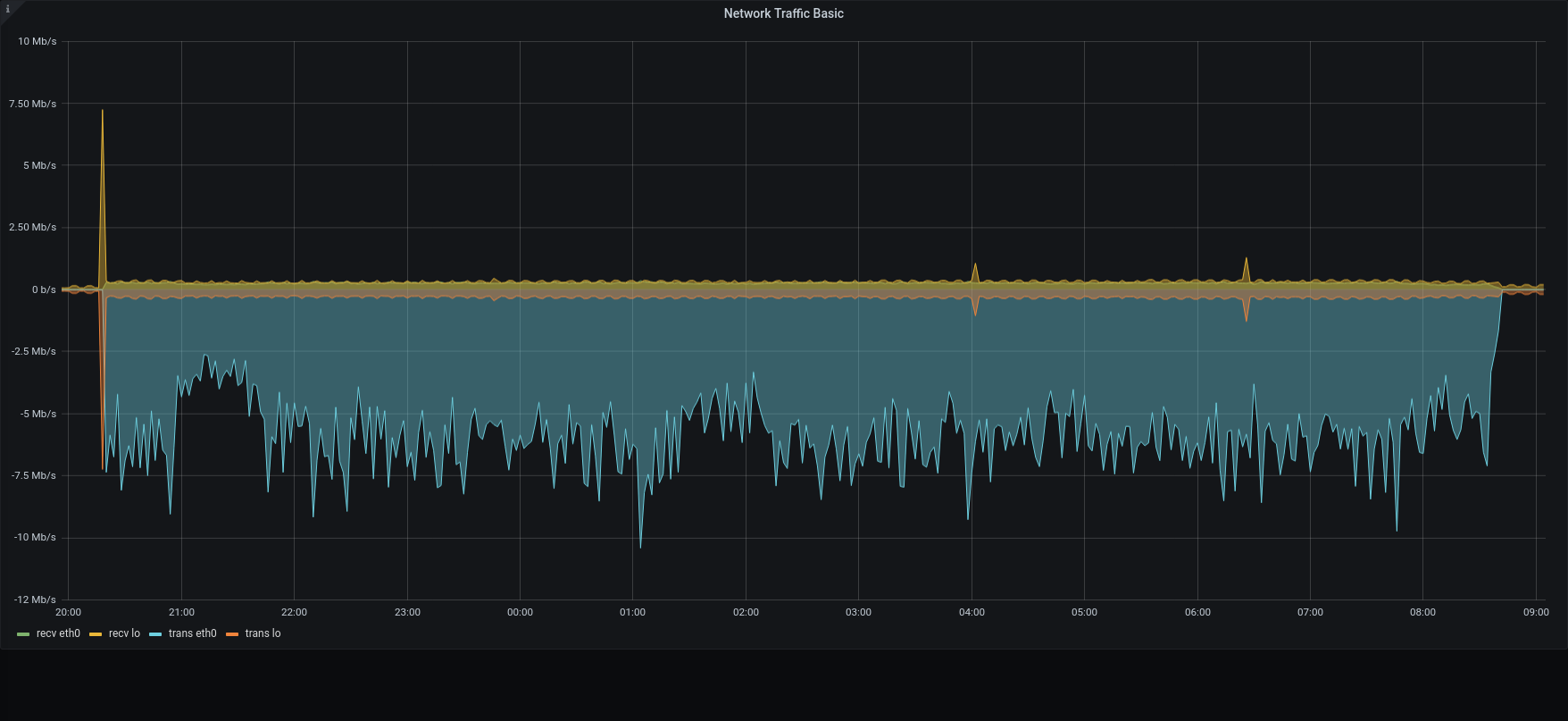 | 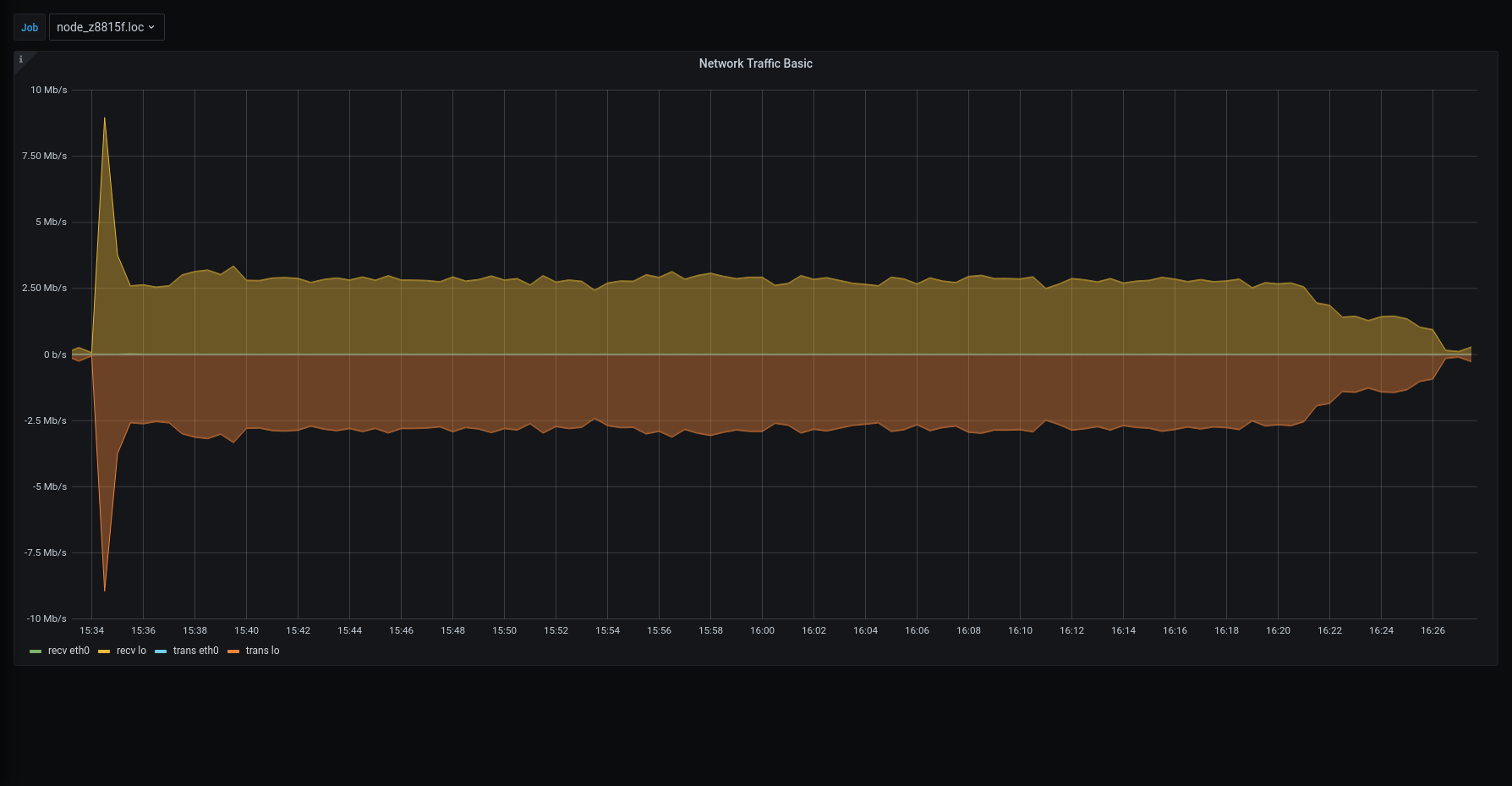 |
| messages | 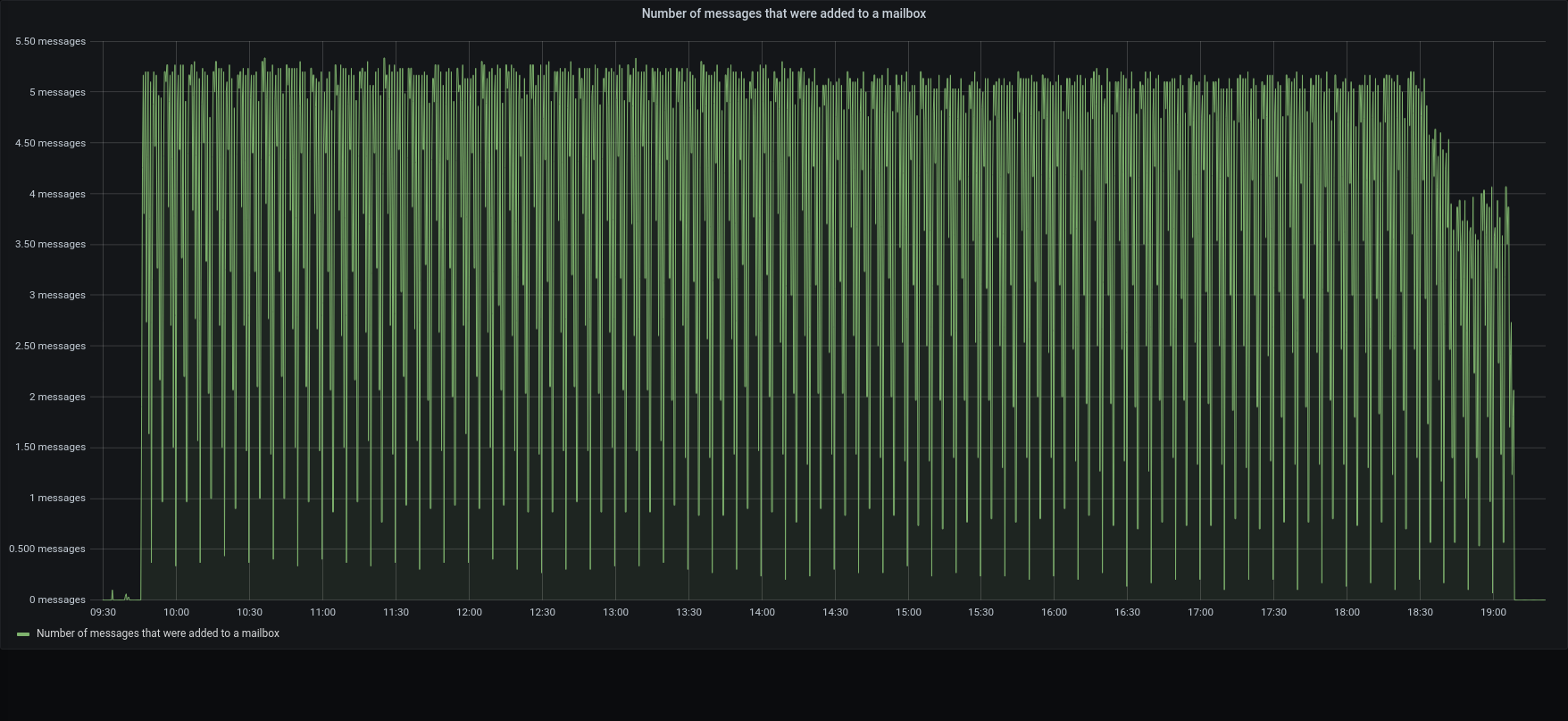 |  |
The restore was executed using the local disk both for metadata and blobs. Both were on SSD, however it should always be possible to move data from a primary volume to an HSM one.
3.1.1 was x4 time faster than previous version in managing the overall process.
We are constantly working on making our backup better and on improving its performances, however, due to its real-time nature, performances are always strictly related to I/O performance.
For this reason, sizing an infrastructure , it’s better to taking care of
- MariaDB and Zextras Metadata random access and IOPS
- backup blobs transfer rate and throughput for sequential access
- number of items for each account
To reduce the storage needed for metadata consider the “external storage option”, which can reduce the local storage by 80%. Doing that will make the restore process faster and more reliable for migration and recovery scenarios
